Trochę w cieniu dzisiejszego szumu wokół sztucznej inteligencji rozwija się rynek rozwiązań low-code i no-code (LCNC), czyli mówiąc po polsku, programowania przez nie-programistów.
Dlaczego? Są ku temu co najmniej trzy dobre powody. Po pierwsze, praca programistów staje się coraz trudniej dostępna, a zatem droższa. Kształcenie nie nadąża za popytem, ponieważ nabycie potrzebnych kompetencji wymaga nie tylko kilkumiesięcznego kursu Pythona, C++, Rubby czy JavaScript, lecz dobrego systemu edukacji od poziomu szkoły podstawowej do matury. Po drugie, biznes musi sprawnie reagować na szybko zmieniające się potrzeby, a rozwiązania IT muszą być coraz bardziej elastyczne i dotychczasowy model tworzenia rozwiązań informatycznych jest zbyt wolny. Po trzecie wreszcie, „teraz już można”. Używając najprostszego przykładu – nie od dzisiaj tworzenie strony www z pomocą programisty jest marnotrawstwem pieniędzy. Aplikacji do ich tworzenia, bez potrzeby napisania linijki kodu, znajdziemy dziesiątki. Dużo ważniejsze niż umiejętności programistyczne stały się kompetencje z obszaru UX, SEO i projektowania graficznego.
Low code, no code – potężny i dynamicznie rosnący nurt w IT
Obecnie w modelu LCNC tworzy się aplikacje mobilne, rozwiązania CRM, e-commerce, Machine Learning (ML), Internet of Things (IoT). W tradycyjnym modelu tworzenia produktów IT niezbędne jest porozumienie się pomiędzy właścicielem procesu w organizacji, który z rozwiązania będzie korzystał, a developerem, który je tworzy. To nie zawsze jest proste, zabiera czas i kosztuje, LCNC likwiduje ten problem.
Citizen Developers rosną w siłę
Programowanie przez nie-programistów staje się powszechne w biznesie (bardziej na świecie niż w Polsce). Tacy nie-programiści mają już swoją nazwę: Citizen Developers. Różne ośrodki analityczne szacują globalną wartość rozwiązań LCNC na koniec 2028 roku na blisko 100 mld USD, a CAGR na tym rynku na ok. 30%.
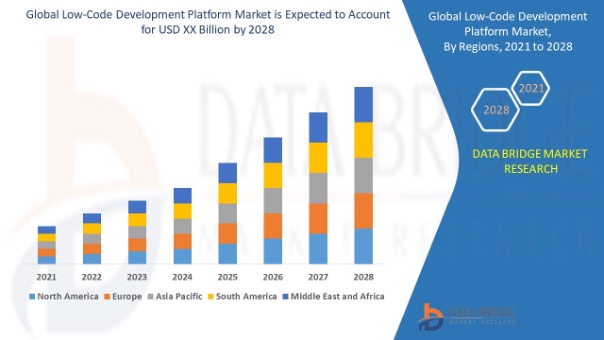
źródło: www.databridgemarketresearch.com
Citizens Data Developers? Czy Big Data także ulega temu uproszczeniu?
Dlaczego piszę o tym na blogu dotyczącym biznesowej analityki danych i korzystania z Qlik Sense? Ponieważ podobne podejście jest potrzebne w Data Science i analityce biznesowej. Podobne są powody, dla których takie łączenie roli konsumenta i producenta jest uzasadnione.
Na marginesie można zauważyć, że sięgając do zamierzchłej historii LCNC spotkamy tam arkusze kalkulacyjne z przełomu XX i XXI wieku, które umożliwiały analizę danych bez znajomości języków programowania.
Nowoczesne narzędzia do analizy danych łączą już w sobie wiele kompetencji
Te same arkusze tkwią u źródeł wszystkich dzisiejszych narzędzi przeznaczonych do analizy danych. W każdym wymiarze potrzebnym w dzisiejszej analityce danych – od czyszczenia i integracji danych, przez ich analizę, predykcje i ML do wizualizacji –aplikacje, z których korzystamy dzisiaj są wielokrotnie bardziej efektywne niż ich pradziadkowie. Jednak założenie, że kompetencje programistyczne nie są niezbędne do korzystania z narzędzi analitycznych pozostało niezmienne.
Qlik Sense i jego nowe, funkcjonalne odsłony
Qlik Sense jako lider rynku ma w tej sprawie bardzo dużo do powiedzenia, a żeby tak było, dokonał w ostatnich latach poważnych inwestycji w rozwój produktu. Używając go możemy podłączać dane bez tworzenia własnych API, a integrować je bez posługiwania się SQL. Nie ma też potrzeby stania się specjalistą Machine Learning do opracowania trafnej predykcji i kończenia studiów artystycznych, aby przygotować komunikatywną wizualizację danych statystycznych. Dzisiaj bardzo zaawansowane analizy i predykcje oparte o ML mogą przygotować nie tylko osoby, które ukończyły studia z obszaru Data Science, ale także nieprofesjonaliści, za to znający dobrze swój biznes.
Co jeszcze umożliwia Qlik Sense SaaS AutoML?
Gdy chcemy przygotować predykcję dotyczącą zachowań naszych klientów na podstawie masowego zbioru danych historycznych, nie musimy wiedzieć na czym polegają i czym różnią się algorytm Random Forest i regresji Lasso (ja na przykład nie wiem). Qlik Sense SaaS AutoML zaproponuje nam nie tylko optymalny model. Możemy też łatwo zobaczyć zmienne, na których Auto ML opiera swoją predykcję i jeżeli jednak uważamy, że jakieś z nich w tej analizie nie mają sensu, to łatwo wyłączymy ich wpływ.
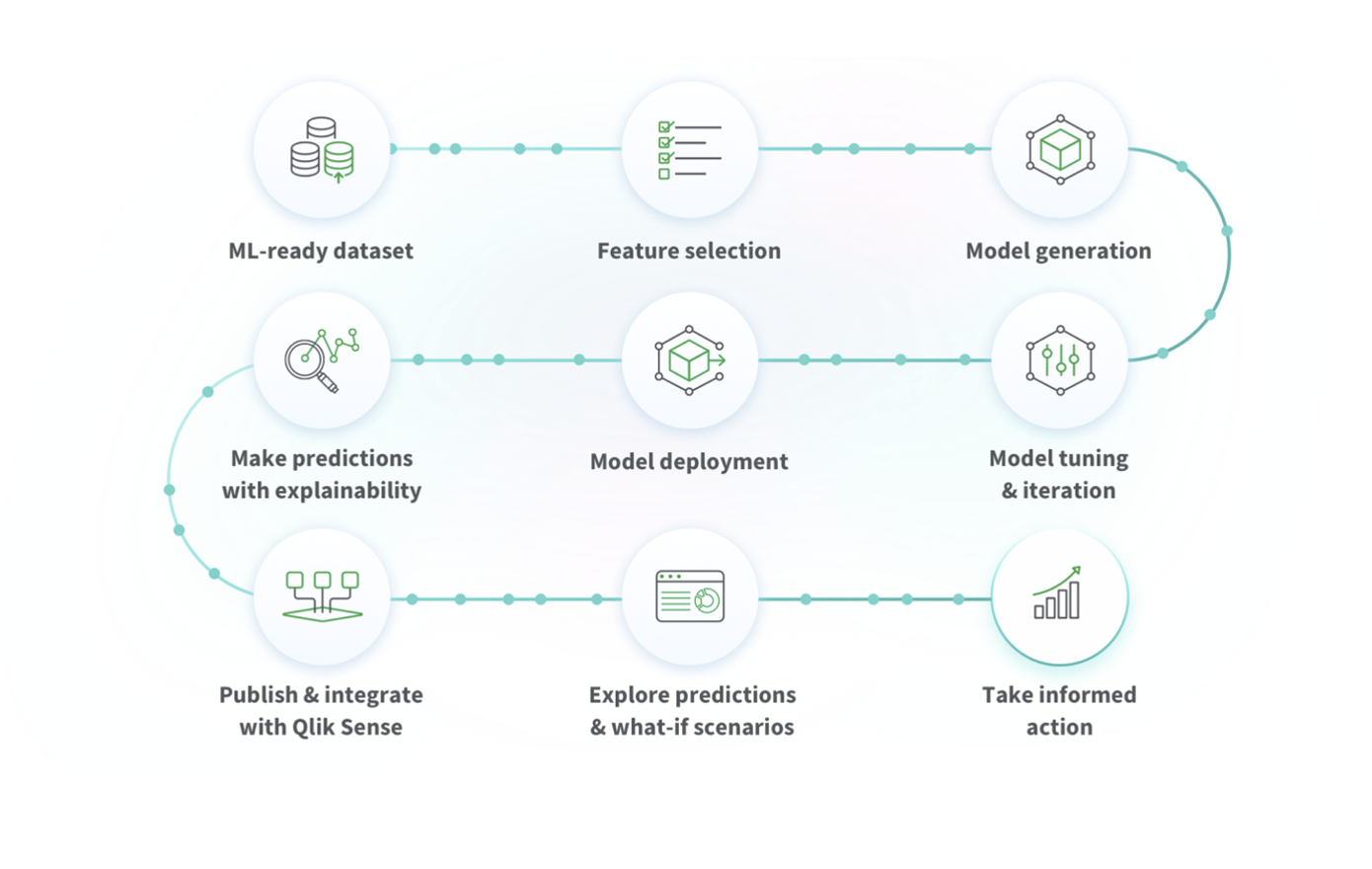
Proces przygotowania predykcji za pomocą AutoML (źródło: qlik.com)
Kiedy korzystać z uproszczeń, a kiedy postawić na w pełni profesjonalne rozwiązania?
Dzisiaj, gdy w firmie trzeba przygotować aplikację służącą do analityki biznesowej, robią to developerzy i analitycy specjalizujący się przede wszystkim w takich zadaniach. Czy warto to zmieniać? Jak w większości zastosowań LCNC, to zależy. Gdy tworzymy rozwiązanie, które ma być używanie w horyzoncie wieloletnim i stanowi element zarządzania kluczowymi procesami firmy, to raczej nie. Jednak przy robieniu prostszych analiz ad hoc albo wąskiego zastosowania, nie ma takiej potrzeby. Co więcej, do przygotowania trafnej predykcji zdarzeń biznesowych coraz częściej zamiast algebry liniowej i statystyki potrzebujemy znajomości własnego biznesu.
Wracając do znaczenia „obywatelskich deweloperów” w firmie, szybki rozwój rozwiązań AI powoduje gwałtowne zmniejszenie bariery kompetencyjnej przy korzystaniu z narzędzi cyfrowych. Coraz częściej ważniejsze jest wiedzieć, co chcemy osiągnąć, a niekoniecznie jak to zrobić, bo w tym drugim pomoże nam maszyna. Citizens Data Science wywodzi się wprost z Citizens Science, czyli uprawiania nauki we współpracy naukowców z nie-naukowcami.
W ten sposób był realizowany np. projekt poszukiwania obcych cywilizacji SETI@Home i dziesiątki innych. Są to znaczące badania naukowe, w których zwykli obywatele stają się badaczami w ramach przedsięwzięcia zaprojektowanego przez akademików. I tak samo warto patrzeć na „obywatelskich analityków danych” w firmach – jak na osoby, które nie tylko korzystają, ale też współtworzą wiedzę opartą na danych.
Praktycy w procesie: interesariusze danych zaangażowani w tworzenie analiz
Podobnie jak przy tworzeniu innych rozwiązań IT, barierą dla rozwoju Data Science są zasoby ludzkie. Możemy je zwiększać włączając w proces tworzenia analiz osoby, które potem z tych analiz korzystają. Przecież każdy manager na „swoje” potrzeby przygotowuje analizy danych i monitoruje KPI, a możliwość zrobienia tego dokładniej i szybciej powinna być dla niego atrakcyjna. W teorii brzmi to pięknie, w praktyce przeważnie jednak przegrywa z business as usual. Wystarczy sprawdzić, ilu jest w naszej organizacji managerów różnego szczebla, którzy do analizy, raportowania i prezentacji danych używają modelu xlc+ppt, bo „zawsze tak robili”.
Zarządzanie zmianą jest tematem zdecydowanie przekraczającym tematykę tego materiału, zatem nie będę udzielał rad, jak z tym business as usual walczyć. Zaryzykuję jednak tezę, że w każdej organizacji są osoby, które z podobnych jak w nauce obywatelskiej powodów (ciekawości, niezrealizowanych ambicji, chęci rozwoju), są w stanie zaangażować się w Citizens Data Science. Szczególnie jeżeli zobaczą, że nie jest to wiedza tajemna, a korzyści z niej płynące w pracy są duże.
Dla osób zajmujących się w firmach analizą danych korzyść będzie dokładnie taka sama, jak w przypadku projektu SETI dla naukowców. Z danych, którymi dysponują można i należy wyciągać wartościowe wnioski, a najszybciej zrobimy to korzystając z podejścia Citizens Data Science.



