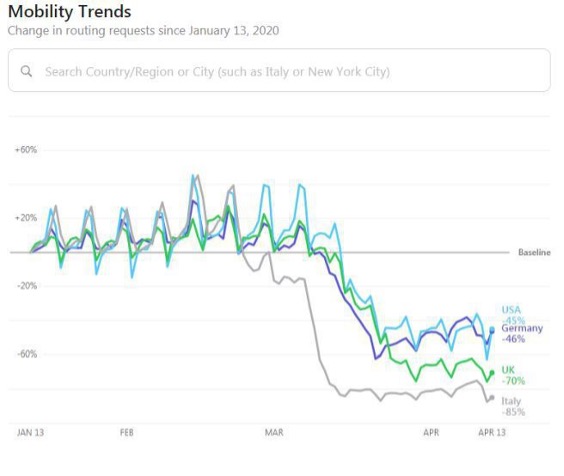
W poprzednich wpisach pokazywałem niepoprawne wizualizacje danych wynikające nie tyle ze złych intencji, co z braku profesjonalizmu. Zgodnie z obietnicą dzisiaj chciałbym przedstawić kilka wykresów i infografik, które spokojnie mogłyby zostać umieszczone w opublikowanej 69 lat temu książce Darrela Huffa „How to lie with statistics?”. Nie zawsze jest oczywiste czy za błędami w wizualizacji danych statystycznych stoi niekompetencja, czy intencja. Dlatego wybrałem takie, w których intencja manipulacji nie budzi wątpliwości.
Nietrudno się zorientować, że w takich praktykach przodują politycy, ale znajdziemy też innych twórców wykresów statystycznych świadomie wprowadzających odbiorców w błąd. Ich wspólną cechą jest to, że autorzy chcą uzasadnić z góry przyjętą tezę za pomocą wizualizacji danych. Przyjrzyjmy się zatem kilku przykładom
Korelacja oznacza jedynie, że istnieje korelacja
Częste jest wnioskowanie na podstawie fałszywej korelacji – istniejącej między zmiennymi, które nie są od siebie zależne. Wiele z nich jest dość zabawnych (niektóre można obejrzeć w tym miejscu: https://www.tylervigen.com/spurious-correlations). Moją ulubioną jest korelacja pomiędzy liczbą filmów z Nicolasem Cage’m, a liczbą utonięć w USA na skutek wpadnięcia do basenu.
Poniżej jeden z bardzo wielu przykładów sytuacji, gdy autor na wykresie korelacje pokazuje, chociaż de facto ona nie istnieje. Problem polega jednak na tym, że autorem tej wizualizacji danych jest Apple, którego trudno podejrzewać o brak kompetencji dotyczących analizy danych.
Źródło: Venngage.com
Skala wszystko wytrzyma?
Kolejny przykład jest wart uwagi nie tylko z tego powodu, że pochodzi z podręcznika szkolnego, ale również, dlatego że Darrell Huffa takiego sposobu kłamstwa nie opisał. Co więcej, autorzy wizualizacji danych statystycznych podpierają się autorytetem wybitnego naukowca.
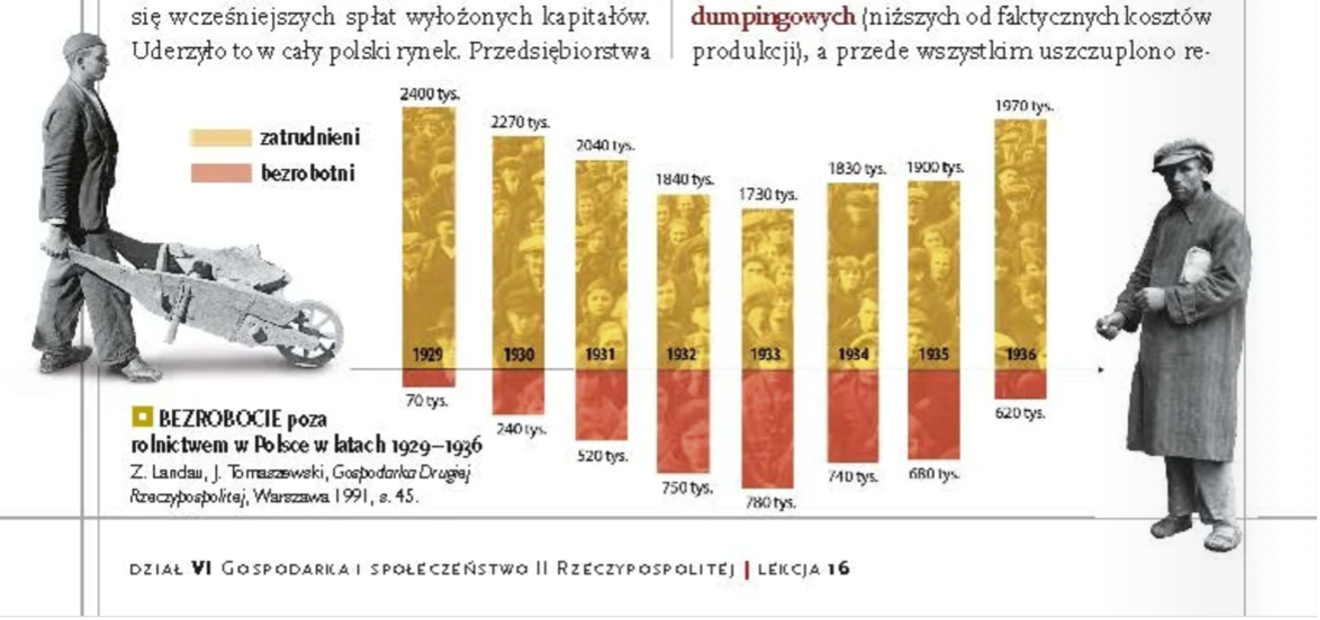
Źródło: „Po Prostu Historia” (https://www.wsip.pl/upload/2016/11/flipbooki_html/155101/index.html#p=18), za Samarter Poland
Trend, którego nie ma?
Statystyki chorób budzą lęk i dlatego dobrze „sprzedają” treści publikowane w mediach. Poniżej kolejna wizualizacja danych statycznych na temat wzrostu liczby chorych na odrę. Jest to świetna ilustracja drugiego, najczęstszego po manipulacji skalą, sposobu kłamania za pomocą statystyk, czyli wybieranie jedynie tych danych, które potwierdzają naszą tezę („cherry picking”).
Telewizja TVN w alarmistycznym materiale dotyczącym wzrostu liczby chorych pokazała wykres, który ma tą tezę uzasadniać. W tym celu z trzynastoletniego szeregu czasowego wybrała jedyne cztery lata, które „potwierdzają” trend wzrostowy.
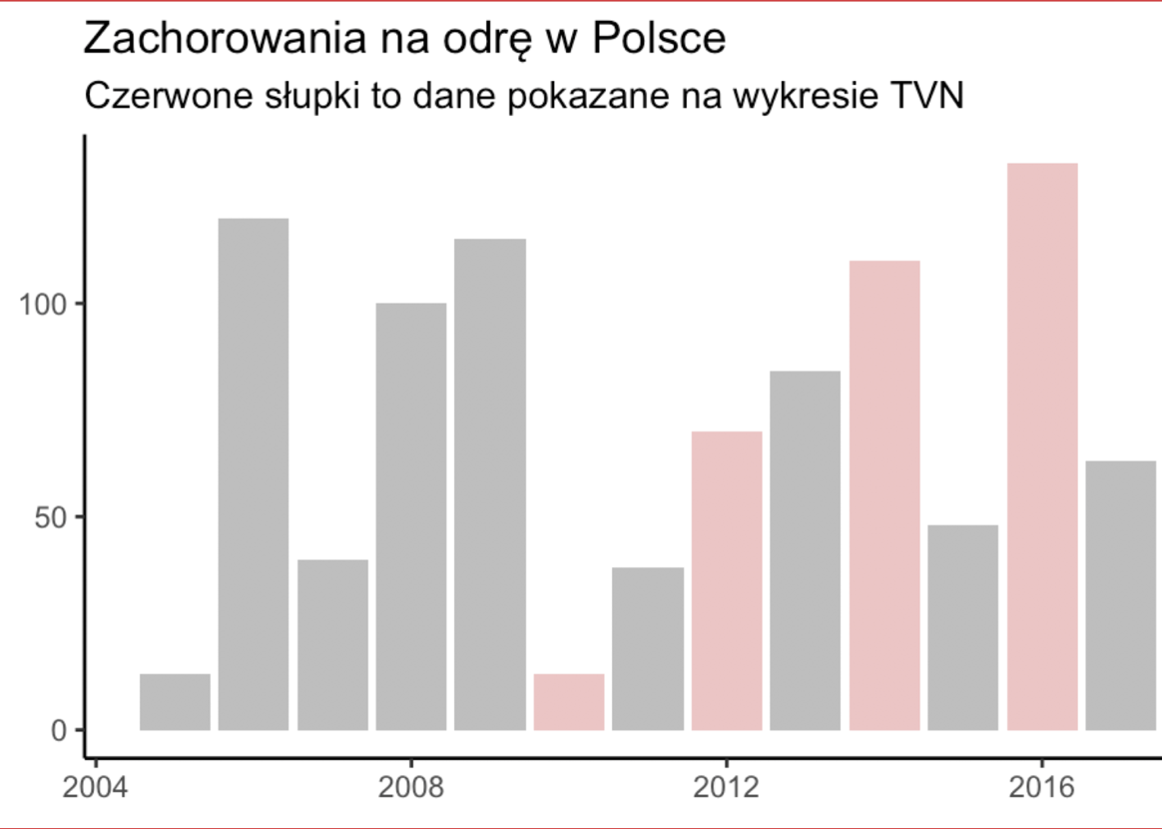
Podana przez TVN liczba zachorowań na odrę w Polsce w latach 2010-2016 (za Smarter Poland)
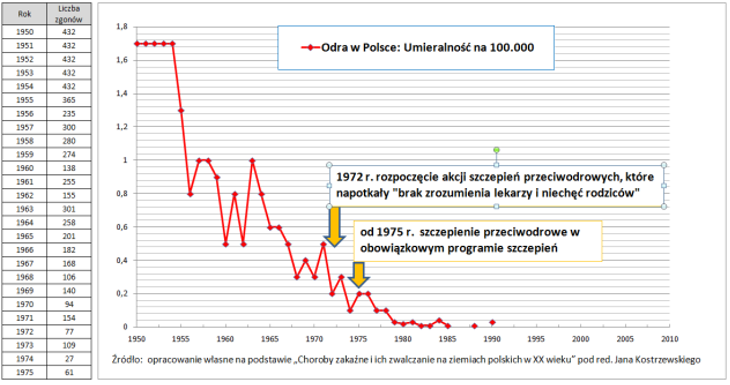
Źródło: pubmedinfo.org
Bardzo dynamiczny wzrost
Poza manipulacją skalą możemy też spotkać manipulacje dynamiką wzrostu. Autorom infografiki poniżej nie wystarcza już pokazanie słupków odciętych na poziomie około 1000 zł. Nie wystarcza wzmocnienie tego zabiegu poprzez prezentowanie wzrostu składki przy pomocy pola i koloru słupka. Zasugerowali też, korzystając ze środków graficznych, geometryczny wzrost składki. Strzałka ponad wykresem pokazuje, że rośnie ona coraz szybciej. Naprawdę wygląda groźnie.
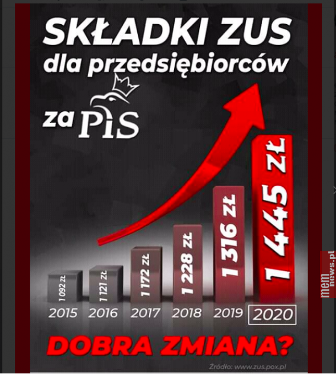
Źródło: Koalicja Obywatelska (za Smarter Poland).

Źródło: KPRM (za fizykwyjasnia.pl)
Źródło: Nature.com
Co jest zaskakujące?
COVID-19 powodował wysyp wizualizacji danych statystycznych, które mniej lub bardziej świadomie wprowadzały w błąd. Zjawisko zrozumiałe, skoro od 100 lat nie mieliśmy do czynienia w pandemią w podobnej skali i nie mamy doświadczeń w mierzeniu takiego zjawiska.
Może stawiam poprzeczkę za wysoko autorom wizualizacji zamieszczonej poniżej, ale Statista to wiodąca firma w obszarze zbierania przetwarzania i udostępniania danych. Niektóre dane udostępniane są bezpłatnie, co służy promocji jej usług.
Tytuł poniższego materiału może wprowadzać nas w błąd, gdyż sugeruje, że nastąpiło jakieś zaskakujące zjawisko…
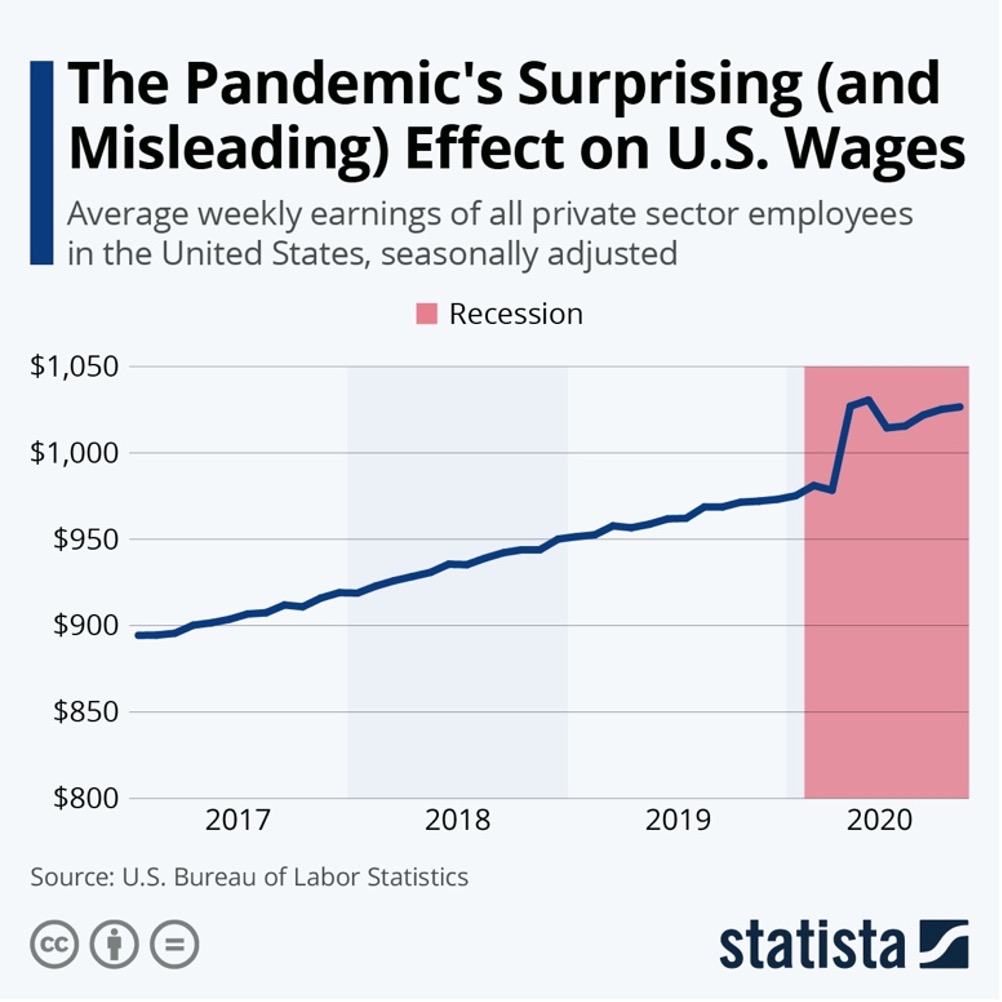
Źródło: Statista

Źródło: The Rand Blog (https://www.rand.org/blog/)
Fake newsy i sposoby na ich obnażenie
Wiele z przykładów, które pokazałem powyżej mogłyby być określone jako fake newsy. Stanowią one ogromny problem dla jakości debaty publicznej, wprowadzają w błąd i wpływają negatywnie na zachowania obywateli. Warto zatem wiedzieć jak zidentyfikować treści, które możemy podejrzewać o to, że są fake newsami.
Jeżeli:
- nie widzimy związku między skorelowanymi zmiennymi,
- na osi czasu są „dziury” dotyczące niektórych okresów,
- widzimy manipulacje skalą,
- całość wygląda zbyt dobrze (pasuje idealnie do tezy),
- obserwacje są prezentowane jako „niezwykłe”
to w takich przypadkach warto sięgnąć do źródła danych, żeby zweryfikować takiego newsa. A jeżeli źródło nie jest podane, to spokojnie możemy założyć, że mamy do czynienia z fake newsem.
W skrócie – możemy przyjąć, że jeżeli coś kwacze jak kaczka, ma dziób jak kaczka i pływa jak kaczka, to najprawdopodobniej jest kaczką.
Zobacz także: Programy do wizualizacji danych



