Rola strategii ESG w nowoczesnym biznesie
Strategię ESG wdraża się w firmach, aby dostosować ich działanie do rosnących oczekiwań społeczeństwa, a także inwestorów. Strategia przyczynia się do ograniczenia ryzyka związanego z aspektami środowiskowymi, społecznymi i zarządczymi, co przekłada się na lepszą stabilność finansową. Ponadto, strategia ESG wspiera długoterminową wartość firmy, przyciągając inwestorów zainteresowanych zrównoważonym rozwojem. Wprowadzenie tych standardów umożliwia również firmom efektywne zarządzanie operacjami, zaspokajanie oczekiwań społeczeństwa oraz uzyskiwanie dostępu do różnorodnych źródeł kapitału.
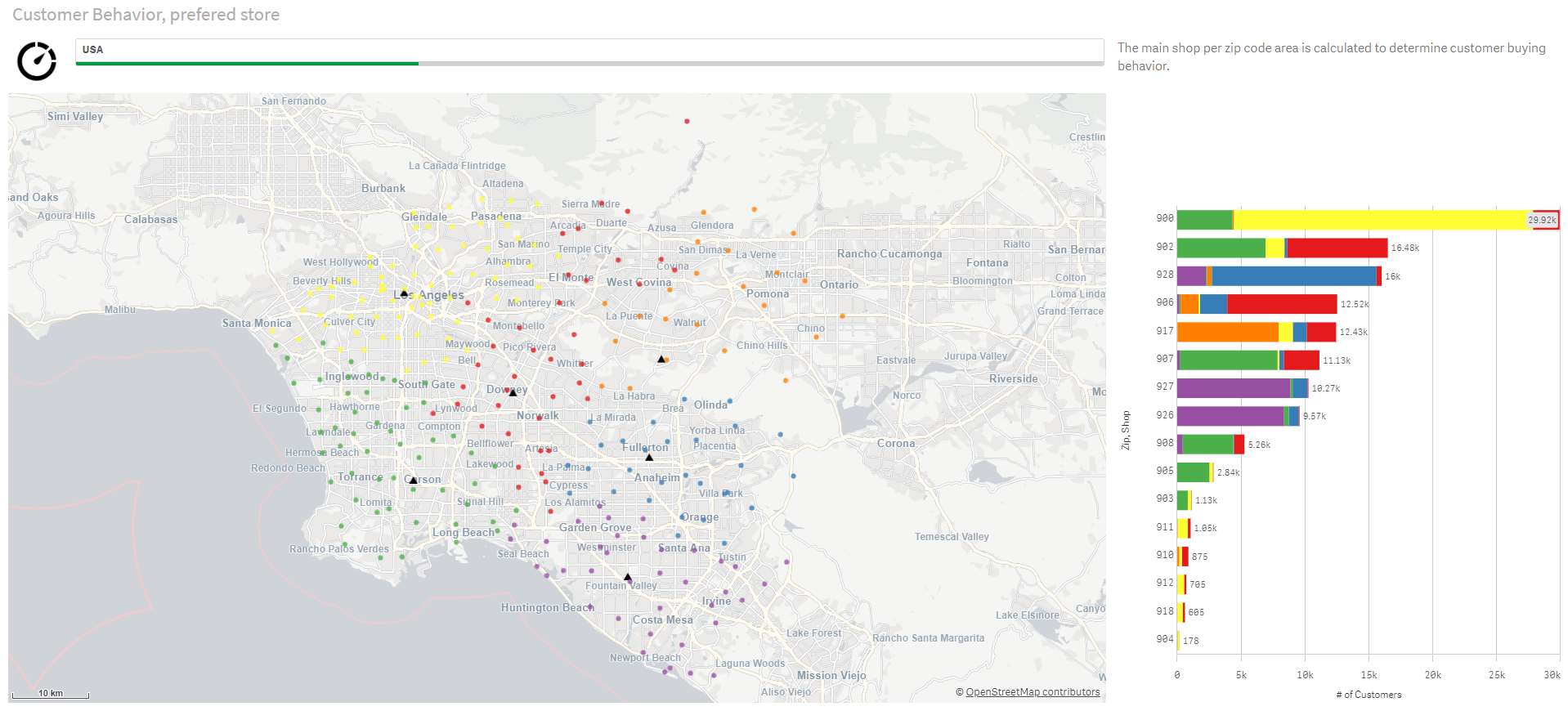
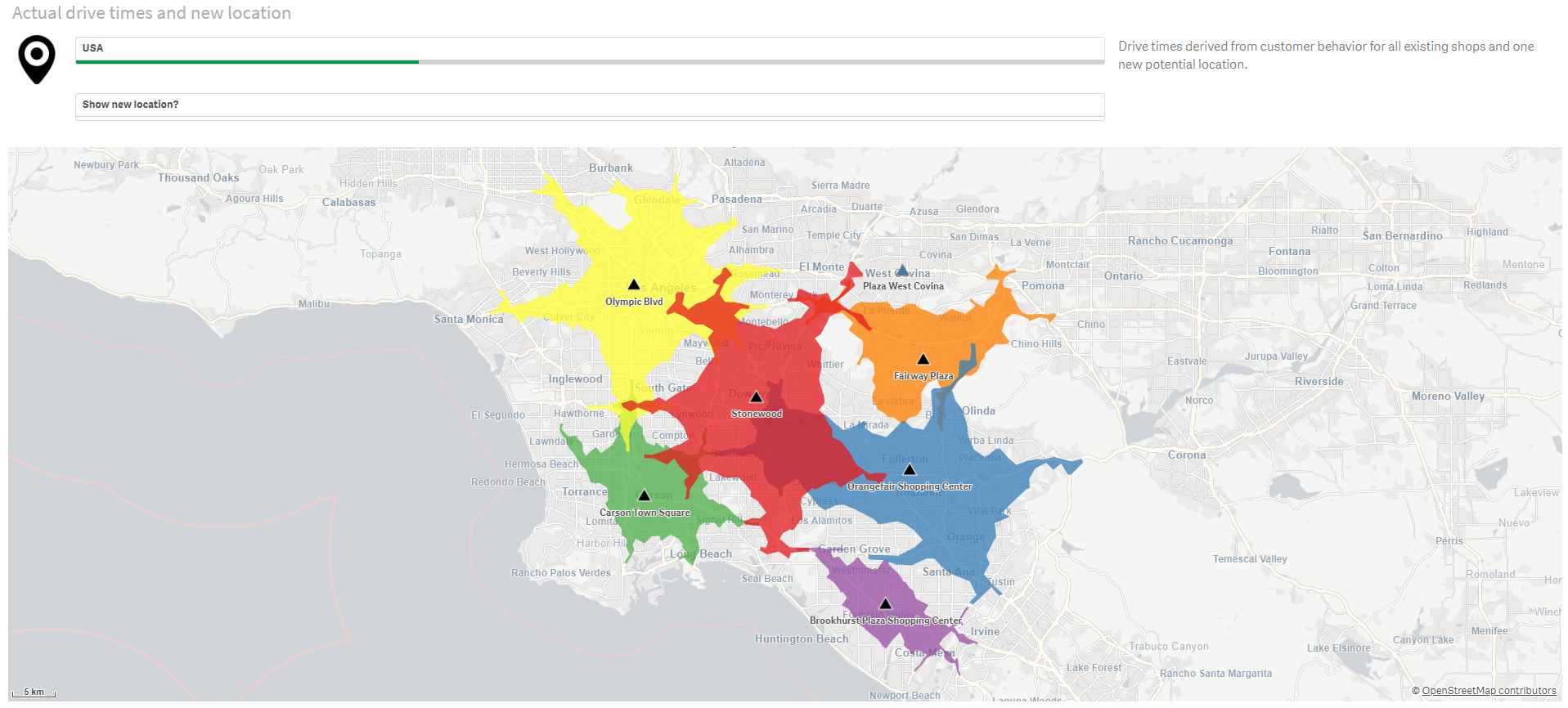
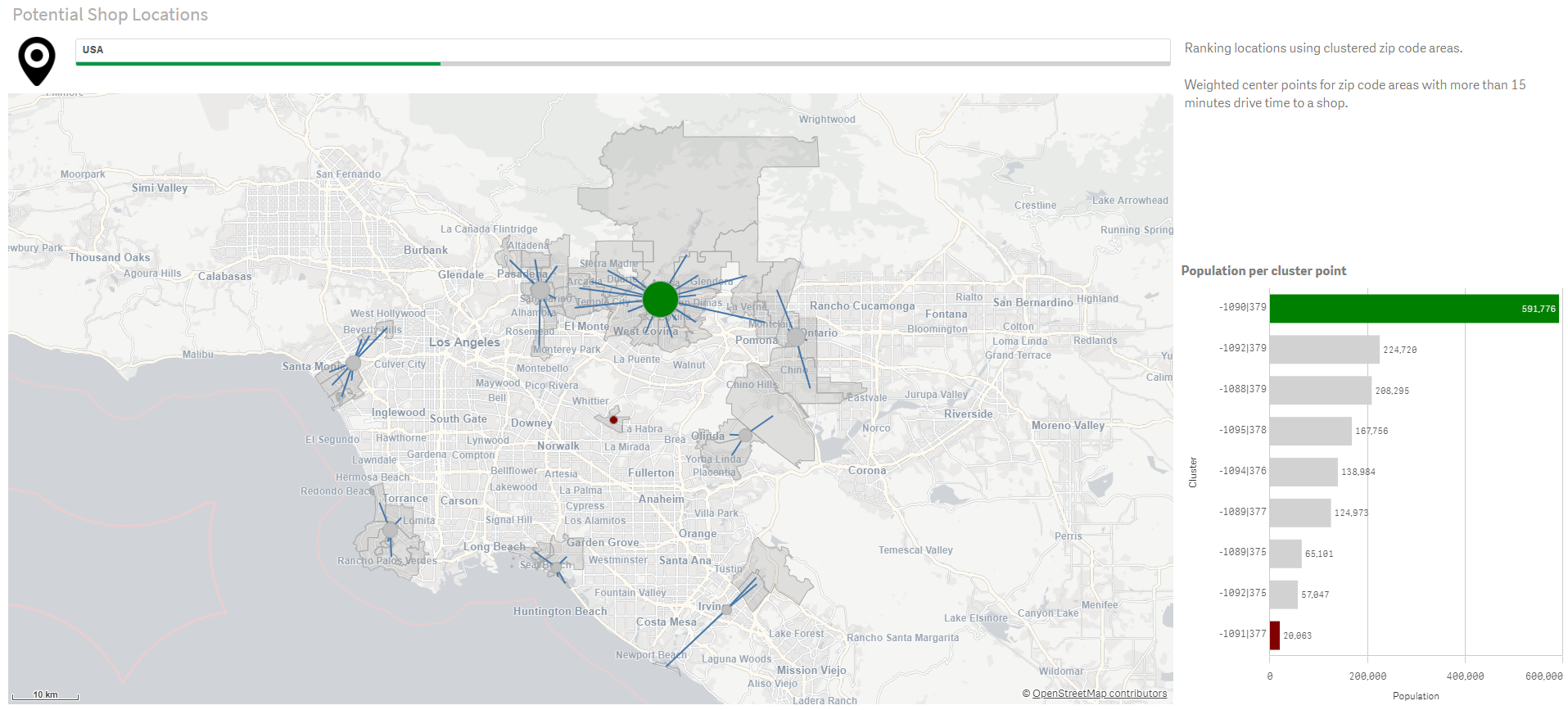
Wiele firm nadal nie wykorzystuje posiadanych zasobów
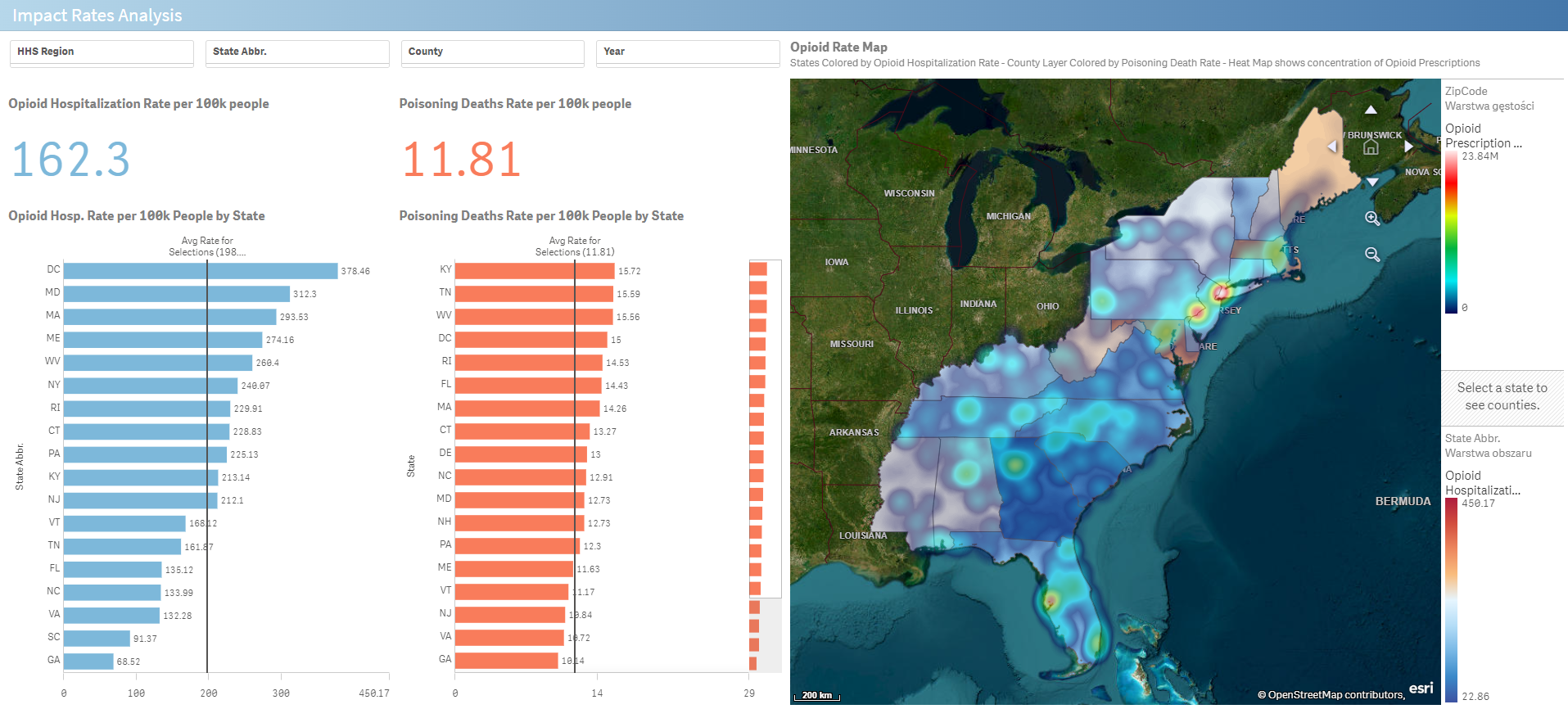
W obliczu dynamicznie zachodzących zmian klimatycznych organizacje intensyfikują wysiłki w obszarach ESG. Istotne jest zrozumienie danych, ale wykorzystanie ich zgodnie z zasadami ESG nadal stanowi wyjątek.
Problem tkwi w dostępie do informacji na poziomie systemów, takich jak SAP. Brakuje skutecznych metod połączenia tych danych dla bardziej wszechstronnej analizy.
Dodatkowo, wiele firm nadal używa arkuszy kalkulacyjnych do gromadzenia danych ESG, co skutkuje raportami opartymi głównie na przeszłości zamiast na informacjach aktualnych. Wysiłki na rzecz zrównoważonego rozwoju są często ograniczone do zespołu ds. ESG, zamiast stanowić integralną część codziennych operacji zachodzących w firmie. Póki co ponad 60% firm zupełnie nie wykorzystuje potencjału ESG, czyli systemów gromadzących, analizujących i raportujących dane z trzech wymienionych obszarów.
Przeczytaj także: Gromadzenie danych trwa. Zettabajty, jottabajty danych – ile z nich wykorzystujemy?
Elementy wpływające na strategię ESG
Długofalowy rozwój firmy oparty na celach zrównoważonego rozwoju, czyli obszarach środowiskowym (Environmental), społecznym (Social) oraz zarządzania (Governance), staje się możliwy dzięki strategii ESG. Istotnym aspektem jest integrowanie strategii ESG z ogólną strategią biznesową organizacji.
- obszar środowiskowy (Environmental):
- wszelkie inicjatywy i praktyki związane ze środowiskiem naturalnym oraz klimatem,
- dążenie do zrównoważonego wykorzystywania zasobów naturalnych i minimalizacji wpływu na ekosystem,
- implementacja strategii proekologicznych mających na celu redukcję śladu węglowego,
- obszar społeczny (Social):
- działania ukierunkowane na ludzi, społeczeństwo i zróżnicowane grupy interesariuszy,
- tworzenie atmosfery współpracy i rozwoju relacji wewnętrznych w organizacji, ze szczególnym uwzględnieniem pracowników,
- zaangażowanie społeczności lokalnych i dialog z interesariuszami w celu zrozumienia ich potrzeb i oczekiwań,
- obszar zarządzania (Governance):
- wdrażanie efektywnych praktyk zarządzania i ładu korporacyjnego,
- ustanawianie przejrzystych struktur decyzyjnych i odpowiedzialności w organizacji,
- promowanie etycznych standardów, zgodności z przepisami prawnymi i uczciwego podejścia do interesariuszy.
Zyski i rozwój firm dzięki wykorzystaniu danych w ramach strategii ESG
#1 Efektywność energetyczna na podstawie danych
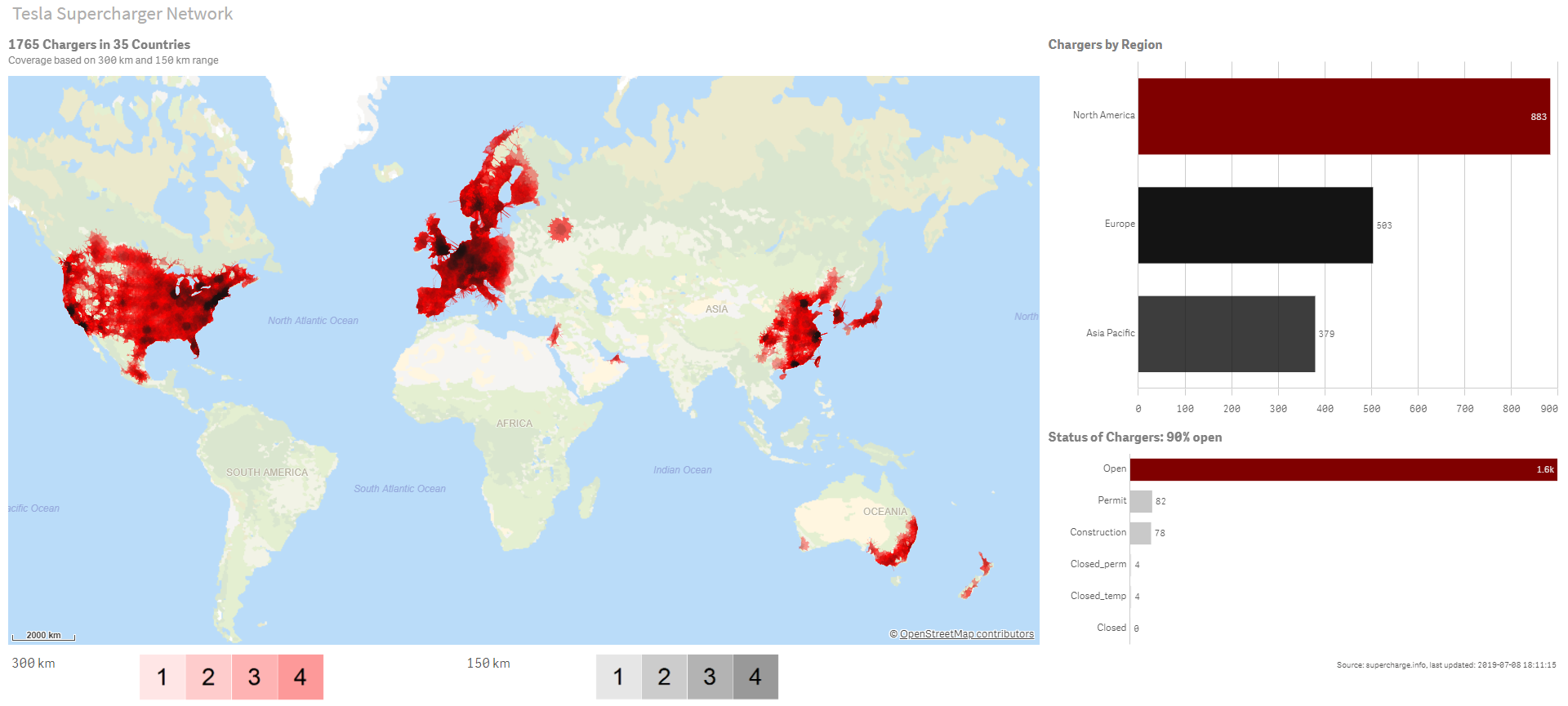
Australijska uczelnia wyższa ANU zobowiązała się do osiągnięcia emisji dwutlenku węgla na poziomie poniżej zera do 2030 roku. Korzystając z analitycznego systemu i pulpitu Qlik uczelnia dąży do pełnego zrozumienia w jaki sposób zużywany jest prąd i gdzie szukać ograniczenia jego zużycia. Placówka zidentyfikowała najbardziej energochłonne obiekty, podejmując świadome decyzje mające na celu redukcję zużycia energii i śladu węglowego. Wdrażane inicjatywy oparte na pomiarze punktów energetycznych pozwoliły zastąpić starsze, bardziej energochłonne obiekty, przyczyniając się jednocześnie do obniżenia kosztów oraz udoskonalenia zgodności z celami zrównoważonego rozwoju ONZ i australijskimi standardami raportowania emisji gazów.
#2 Odpowiedzialność społeczna poprzez analizę danych społecznych
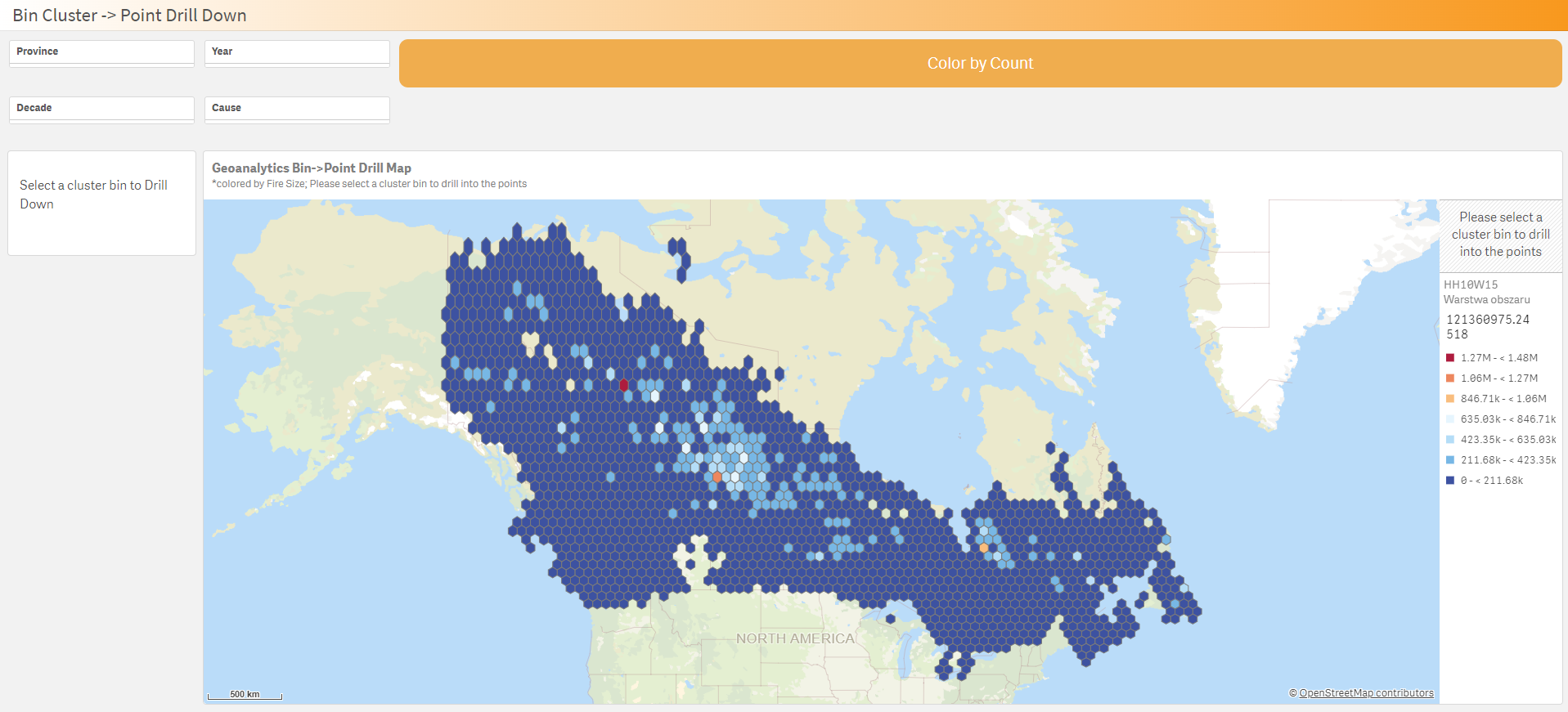
Nowozelandzka firma The New Zealand Merino Company (NZM) wyznacza standardy w etycznej produkcji wełny, skupiając się na jakości włókien, dobrostanie zwierząt oraz odpowiedzialności społecznej i środowiskowej. Ich innowacyjny indeks rolnictwa regeneracyjnego (RX) umożliwia rolnikom działanie zgodnie z zasadami zrównoważonego rozwoju, a wykorzystanie narzędzia Qlik do modelowania i wizualizacji danych pozwala NZM efektywnie monitorować emisje dwutlenku węgla z 600 gospodarstw, oszczędzając przy tym setki tysięcy dolarów. Zatem NZM nie tylko oszczędza, ale również podejmuje świadome decyzje w kierunku doskonalenia procesów produkcji i minimalizacji negatywnego wpływu na środowisko.
#3 Zarządzanie łańcuchem dostaw
Fundacja Crossroads z Hongkongu dążąc do płynnej transformacji społecznej, dystrybuuje darowizny w postaci towarów, technologii i środków medycznych w 90 krajach. Wykorzystując platformę analityczną Qlik Sense, skróciła czas reakcji na propozycje darczyńców do mniej niż godziny, co znacznie przewyższa standardowe pięć dni roboczych. Dzięki modelowi SaaS Fundacja osiągnęła nie tylko efektywność w obszarze logistyki, organizacji łańcucha dostaw, ale także zmniejszyła zużycie energii.
#4 Redukcja ryzyka i poprawa zarządzania
Firma Van Oord, z ponad 150-letnim doświadczeniem w projektach morskich, wprowadza innowacyjne rozwiązanie dla społeczności na obszarach przybrzeżnych. Korzystając z platformy Qlik Analytics Platform®, stworzyła aplikację Climate Risk Overview, mapującą globalne dane dotyczące ryzyka powodzi. Dzięki przeglądowi sytuacji, obejmującemu kluczowe parametry, użytkownicy mogą przewidywać zagrożenia powodziowe na całym świecie. Efektem końcowym jest publicznie dostępna aplikacja, będąca pierwszym krokiem w szerokim planie adaptacyjnych rozwiązań dla obszarów nadmorskich dotkniętych zmianami klimatycznymi.
#5 Wzrost kapitału ludzkiego
W środowisku biznesowym wiele rad dyrektorów skupia się na kwestiach z obszaru ESG, szczególnie związanych z pracownikami. Dyskusje obejmują różnorodność, równość, dobrostan pracowników oraz elastyczne modele pracy. Pandemia przyspieszyła te trendy, ale zmiany demograficzne, transformacja cyfrowa i konkurencja na polu pozyskiwania talentów były już wcześniej ważnymi tematami. „Wielka rezygnacja” z pracy w USA podkreśliła, że pracownicy mają kluczowy głos w kwestiach zatrudnienia. Firmy reagują na te zmiany, rozważając elastyczne modele zatrudnienia, dostosowując się do potrzeb pracowników i wykorzystując technologie cyfrowe. Rady dyrektorów odgrywają coraz ważniejszą rolę w opracowywaniu strategii zarządzania kapitałem ludzkim, co przekłada się na adaptację przedsiębiorstw do nowych modeli pracy i zwiększenie innowacyjności.
#6 Efektywność kapitałowa dzięki danym finansowym ESG
W ostatniej dekadzie sektor finansowy zauważa dynamiczne przesunięcie od krótkoterminowej maksymalizacji zysków na rzecz długoterminowego modelu zrównoważonego rozwoju. Czynniki ESG, obejmujące aspekty społeczne i środowiskowe, stają się decydującym czynnikiem umożliwiającym ocenę wartości przedsiębiorstwa przez inwestorów i dostawców usług finansowych. Zarządzanie ryzykiem ESG wpływa na bilans spółki, a rosnące zainteresowanie instrumentami finansowymi, takimi jak zielone obligacje czy kredyty związane ze wskaźnikami ESG, ściśle wiąże koszty finansowania z wynikami w obszarach zrównoważonego rozwoju. Emitenci ujawniając dane ESG, efektywnie zarządzają ryzykiem biznesowym, zdobywając jednocześnie korzystne warunki finansowania, co pozwala im skutecznie przystosować się do transformacji i uzyskać wsparcie inwestorów.
#7 Kreowanie wartości marki poprzez transparentne raportowanie danych ESG
Transparentne raportowanie danych ESG to istotny czynnik kreowania wartości marki. Przedsiębiorstwa, które aktywnie angażują się w opracowywanie raportów odnoszących się do ich działań związanych ze środowiskiem, społecznością i ładem korporacyjnym, eliminują nie tylko ryzyka związane z niewłaściwym zarządzaniem, ale również zdobywają zaufanie inwestorów. ESG umożliwia spółkom identyfikację obszarów do doskonalenia, co prowadzi do ograniczenia emisji dwutlenku węgla, efektywnego zarządzania zasobami oraz zwiększenia innowacyjności. Poprzez przejrzyste przekazywanie informacji, przedsiębiorstwa nie tylko spełniają oczekiwania rynkowe, lecz także budują trwałą reputację opartą na wartościach zrównoważonego rozwoju.
#8 Zarządzanie skutkami zmian klimatycznych
Deloitte wdrażając strategię WorldClimate, łączy podróże służbowe z osiąganiem globalnych celów klimatycznych. Belgijska jednostka firmy wykorzystując interdyscyplinarny program z aplikacją Qlik, precyzyjnie monitoruje emisję dwutlenku węgla związaną z podróżami służbowymi pracowników. Prosty i intuicyjny pulpit nawigacyjny zwiększa świadomość programu i inspiruje do zdrowej konkurencji między jednostkami. W rezultacie firma odnotowuje imponujące obniżenie emisji CO2 o 10% w pierwszym roku realizacji programu.
Podsumowanie – jaka jest przyszłość strategii ESG?
ESG to skrót od Environmental, Social, Governance, co oznacza uwzględnianie kwestii związanych ze środowiskiem, społeczeństwem i zarządzaniem w podejmowanych przez firmy decyzjach. Strategia ESG nie tylko wytycza kierunki, w jakich rozwija się biznes, ale również zmienia podejście do zrównoważonego rozwoju w porównaniu z tradycyjnymi strategiami.
Innowacyjne podejście umożliwia dokładne monitorowanie postępów poprzez systematyczne raportowanie ESG. Dzięki temu przedsiębiorstwa mogą skutecznie zarządzać swoim wpływem na wymienione wyżej obszary, co przekłada się na rzeczywiste osiąganie założonych celów zrównoważonego rozwoju.
Przyszłość strategii ESG rysuje się obiecująco, wskazując na rosnące znaczenie zrównoważonego rozwoju w biznesie. Organizacje coraz efektywniej integrują cele środowiskowe, społeczne i ładu korporacyjnego w swoje strategie, dążąc do efektywnego zarządzania ryzykiem i tworzenia wartości. W miarę postępującej globalnej świadomości ekologicznej oraz wzrostu oczekiwań społeczeństwa, strategie ESG stają się nie tylko narzędziem prowadzącym do ograniczania negatywnego wpływu, lecz także istotnym czynnikiem prowadzącym do budowania trwałego sukcesu biznesowego i społecznego.