Wolumen zgromadzonych na świecie danych powoli przestaje robić na nas wrażenie. 120 zettabajtów, które zbierzemy do końca tego roku są równie abstrakcyjne, jak 1 jottabajt, który powinniśmy osiągnąć za 10 lat. Łatwiej więc mówić o szansach, zagrożeniach i korzyściach tego, że dostępnych danych jest niewyobrażalnie dużo. Tych którzy chcieliby mieć bardziej konkretną wiedzę na temat charakterystyki tych zbiorów odsyłam do raportu The Digitization of the World From Edge to Core opracowanego przez IDF. Został on wprawdzie opracowany w 2018 roku, jednak jego wnioski są cały czas aktualne.
Zagrożenia wynikające z gromadzenia danych
Zacznę od wskazania zagrożeń, z których warto sobie zdawać sprawę. Szybki wzrost wolumenu danych rodzi dwa istotne zagrożenia, które tylko pozornie nie dotyczą biznesu:
- Po pierwsze, są to koszty klimatyczne. Funkcjonowanie serwerów jest bardzo energochłonne ze względu na konieczność ich chłodzenia. Wprawdzie, ostatnio pojawiły się informacje o stworzeniu nadprzewodników działających w temperaturze pokojowej, jednak dopóki nie pojawią się one w praktycznych zastosowaniach, proponowałbym traktować je bardziej jako ciekawostkę, niż rozwiązanie problemu carbon footprint serwerów.
- Po drugie, są to zagrożenia prywatności. Ochrona danych wrażliwych stanowi problem nie tylko dla biznesu. Kwestie te są tak istotne społecznie i politycznie, że coraz silniejsze są regulacje dotyczące przechowywania i wykorzystywania danych. Oczywiście ten problem nie dotyczy Chin (i innych reżimów autorytarnych), gdzie państwo opiera nadzór obywateli na analizach masowych danych w czasie rzeczywistym, ale tu mamy monopol państwa na wykorzystywanie danych.
To tematy na oddzielne wpisy, jednak warto mieć je z tyłu głowy, chociażby dlatego, że regulatorzy mogą z tych powodów nakładać ograniczenia i opłaty za gromadzenie i przetwarzanie danych.
Gromadzimy dane, które „do niczego nie służą”
Wróćmy jednak do problemu (nie)wykorzystania dostępnych danych. Wolumen danych rośnie w tempie wykładniczym – 1,5-krotnie co dwa lata. Łatwo tu zauważyć analogię do prawa Moora. To zresztą wskazuje, że nie moce obliczeniowe są największą barierą dla wykorzystania danych, którymi świat dysponuje. Moce obliczeniowe rosną szybciej i wcale nie poprawia to odsetka wykorzystywanych zasobów. Szacuje się, że tylko w biznesie nie wykorzystuje się ¾ posiadanych przez firmy danych. A są przecież jeszcze dane gromadzone w urządzeniach końcowych, czy dane w rejestrach publicznych lub dane z obserwacji naukowych.
Ograniczeniem nie wydają się także ceny rozwiązań IT służących do analizy danych. Dostęp nawet do tych najbardziej zaawansowanych można mieć w formule SaaS za kilkadziesiąt dolarów miesięcznie.
Oczywiście istotną barierą jest jakość danych i różnorodność platform oraz formatów ich gromadzenia. To zadanie dla dostawców rozwiązań, a nie ich użytkowników. Jednak sytuacja tu na pewno się poprawia. Przykładem jest przejęcie Talend przez Qlik, a przypomnijmy, że obie firmy od wielu lat są liderami rynku w swoich kategoriach. Qlik wśród platform Analizy Danych i Business Intelligence, a Talend integracji i zarządzania danym. Na takiej pozycji są systematycznie umieszczane w Gartner Magic Quadrant

Bariery w efektywnym wykorzystaniu gromadzonych danych
Chciałbym jednak zwrócić uwagę na często niedostrzegane bariery. Czynniki mające wpływ na wykorzystania zasobów w dużej części mają charakter „miękki”, a najsłabszym ogniwem w tym obszarze okazuje się człowiek. Trzeba tu wskazać na kilka obszarów:
- Kompetencje.
Po pierwsze, chodzi o podnoszenie poziomu wiedzy i umiejętności menadżerów średniego szczebla (life long learning!), tak aby Business Intelligence stało się elementem ich kluczowych kompetencji. - Zmiana sposobu myślenia o danych w organizacji.
Data Driven Company nie polega jedynie na stworzeniu działu Data Science, tylko na wprowadzeniu praktyki nowoczesnych analiz danych do codziennej działalności firmy. Demokratyzacja danych oznacza nie tylko to, że otwartych danych jest coraz więcej, ale także to, że coraz więcej osób potrafi wyciągać z danych wnioski. - Odejście od business as usual.
Łatwiej zbudować kulturę i praktyki funkcjonowania firmy od zera niż zmienić utrwalone schematy postępowania, jednak w czasach szybkich zmian technologicznych trudno tego uniknąć. Przykładów firm wielkich i małych, które upadły z tego powodu jest wielu (pewnie najbardziej znanym jest Kodak). - Last but not least, edukacja powszechna.
Temat zdecydowanie nie na ten blog, jednak każdy kto szukał pracowników z przyzwoitymi kompetencjami matematycznymi, wie o czy mówię. Matematyki bardzo trudno jest nauczyć osób dorosłych, a edukacja matematyczna w szkołach pozostawia bardzo wiele do życzenia. Wykres wyników ostatniego egzaminu 8-klasistów pokazuje skalę tego problemu.

Trudno przełamać prymat Excela i Power Pointa jako narzędzi do analizy i prezentacji danych
Trudno dzisiaj spotkać w jakimkolwiek biurze pracownika, który nie posługuje się arkuszem kalkulacyjnym czy programem do prezentacji (chociażby na podstawowym poziomie).
I właśnie tych narzędzi używa się dzisiaj do analiz danych i prezentowania ich wyników. To tak jakby w 1990 roku nadal korzystać z maszyny do pisania, aby przygotowywać raporty, a w 2000 używać amerykanki do księgowania. Dostępnych jest co najmniej kilka rozwiązań, za pomocą których zrobimy dużo bardziej precyzyjne analizy i predykcje, a ich wyniki zaprezentujemy bardziej komunikatywnie i perswazyjnie. Opanowanie korzystania z tych aplikacji na poziomie średniozaawansowanym nie jest dużo trudniejsze niż uzyskanie podobnych kompetencji korzystania z Excela i innych popularnych arkuszy kalkulacyjnych.
Dlaczego firmy nie wykorzystują zgromadzonych danych? Insighty rynkowe
Żeby nie było zbyt teoretycznie, trzy przykłady, jak wygląda praktyka w Polsce. Firmy, które opisuję istnieją naprawdę:
Duża firma z branży usług finansowych (kilka tysięcy zatrudnionych).
Dyrektor jednego z pionów przygotowuje dla zarządu cykliczne materiały zawierające analizy statystyczne. Nie są to predykcje, jednak to na ich podstawie podejmowane są istotne decyzje biznesowe. Materiały opracowuje za pomocą arkusza kalkulacyjnego, czasem też wkłada wykresy do nieśmiertelnego Power Pointa. Dlaczego? Bo „zawsze tak robił”. Nawet słyszał o bardziej nowoczesnych rozwiązaniach, ale raczej nie da się do nich przekonać. Ewentualnie może zwróci się do działu Data Science o przygotowanie mu jakiegoś rozwiązania IT. Chociaż bez entuzjazmu.
Nieduża firma badań opinii i rynku.
Od początku swojego istnienia zarówno analizy, jak i prezentacje badacze przygotowują wyłącznie za pomocą pakietu MS Office. Wprawdzie firma zaczęła sięgać po jedną z aplikacji stosowaną w analizach danych, jednak wyłącznie do prezentowania wyników i tylko w formule outsourcingu (zamawiają dashboardy oparte na arkuszach kalkulacyjnych). Pytani, dlaczego nie chcą tego zmienić, mówią, że klienci „oczekują od nich takiego standardu prezentacji wyników, ponieważ chcą mieć je w formie łatwej do przekopiowania do swoich prezentacji”. Zdecydowanie natomiast „nie mają czasu uczyć się czegoś nowego”. W ten sposób o firmie, która z natury swojej działalności zajmuje się analityką danych trudno byłoby powiedzieć, że jest data driven. Nie mówiąc o sięganiu po socjologię cyfrową, która zajmuje się wnioskowaniem na podstawie masowych zbiorów danych. O samej socjologii cyfrowej i analizach danych publicznych napiszę w kolejnym wpisie.
Średniej wielkości firma, przedstawiciel i dystrybutor kilku marek (handel hurtowy, a ostatnio także BTC).
W działalności oczywiście wykorzystuje specjalistycznie oprogramowanie CRM do zarządzania stanem magazynów oraz łańcuchami dostaw. Jednak analizy i zestawienia pomagające w prognostyce biznesowej są robione za pomocą arkusza kalkulacyjnego. Z oczywistych powodów firma potrzebuje predykcji dotyczących zakupów i sprzedaży, zwłaszcza, że łańcuchy dostaw są długie. Oczywiście słyszeli o rozwiązaniach służących do analiz danych i predykcji na ich podstawie, jednak na wdrożenie takich narzędzi brakuje czasu. W konsekwencji decyzje biznesowe podejmowane są bardziej na podstawie arkusza kalkulacyjnego i gut feeling, niż w oparciu o analizy i predykcje wykorzystujące dostępne dane.
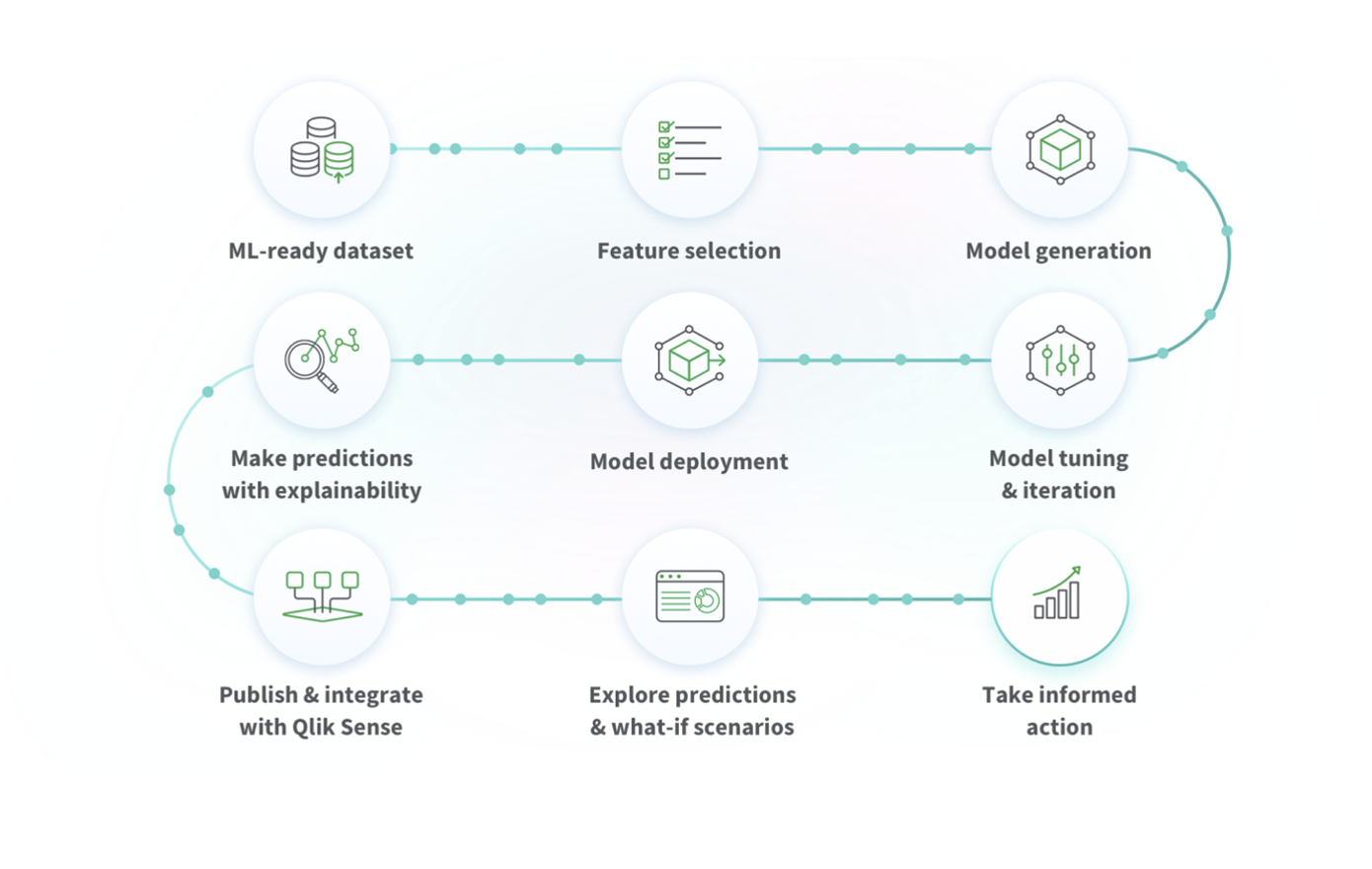
Takich przykładów niewykorzystanych szans można znaleźć dużo. Wiele firm ma jeszcze długą drogę od etapu, gdy zaczną korzystać z Machine Learning. Jednak już sama zmiana praktyki mikroanaliz zarówno danych statystycznych, jak i rejestrów zdarzeń, bardzo przybliżyłaby je do takiego momentu. Szczególnie jeśli zdecydowaliby się na Qlik Sense, a to ze względu na AutoML ułatwiający robienie zaawansowanych analiz bez konieczności kończenia studiów Data Science.
Nie wiem, czy firmy te podzielą los dinozaurów, ale prawdopodobieństwo, że tak się stanie nie jest zerowe. Zdaję sobie sprawę, że zmiana wymaga wysiłku, ale jeżeli myślimy w perspektywie dłuższej niż jednoroczny wynik, warto go podjąć. Przeprowadzenie tej zmiany w obszarze Data Science jest drogą do tego, aby rozwiązać problem gromadzonych danych, które „nie służą do niczego”.