Artykuł przedstawia kroki pozwalające na wykonanie analizy koszykowej, na przykładzie analizy danych o sprzedaży produktów.
Proponujemy stopniowe rozszerzanie projektu. Rozpoczęcie od przećwiczenia wykonywania tylko analizy w Pythonie, a następnie włączenie Qlika dla łatwiejszego przygotowania danych wejściowych. Później po użycie Qlika do analizy wyników, ale jeszcze z przesyłaniem wyników analizy koszykowej za pomocą plików. Ostatnim etapem będzie wykorzystanie konektora SSE, który pozwala na wymianę danych pomiędzy Qlikiem i Pythonem w tle, w trakcie pracy aplikacji analitycznych.
Etap 1. Analiza koszykowa w Pythonie
Wykonanie analizy wymaga przygotowania środowiska, przygotowania danych oraz wywołania funkcji dokonującej właściwej analizy.
1. Przygotowanie środowiska
Jednym z najpopularniejszych środowisk do analizy danych jest obecnie Jupyter Notebook. Aby utworzyć środowisko należy najpierw zainstalować pythona najlepiej w wersji 64 bitowej.
Analiza jest wykonywana w środowisku Windows dlatego linki będą dotyczyły tego środowiska. Wszystkie wersje na Windows są zebrane pod poniższym linkiem:
https://www.python.org/downloads/windows/
Często zdarza się że biblioteki dla data science lub machine learning nie są na bieżąco z najnowszymi wersjami pythona, dlatego lepiej zainstalować nieco starszą wersję 3.8 lub 3.7. W analizie koszykowej będzie wykorzystywana wersja 3.8 64bit dostępna pod linkiem:
https://www.python.org/ftp/python/3.8.10/python-3.8.10-amd64.exe
Po zainstalowaniu pythona należy zainstalować następujące biblioteki poniższymi komendami z linii poleceń Windows:
pip install pandas
pip install mlxtend
pip install notebook
Następnie uruchamiamy środowisko webowe notebook z poziomu linii poleceń Windows:
jupyter notebook
Pierwszym krokiem jest zaimportowanie wymaganych bibliotek. Biblioteka pandas służy głównie do wciągnięcia danych z pliku csv lub xlsx a następnie przygotowaniu danych w formacie wymaganym przez biblioteki właściwe odpowiedzialne za analizę koszykową.
import numpy as np
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
pd.options.mode.chained_assignment = None # default='warn'
2. Załadowanie danych
Do wykonania analizy koszykowej potrzebny nam będzie dowolny zbiór danych o transakcjach sprzedaży, ograniczony do dwóch informacji: identyfikatora transakcji i identyfikatora produktu.
Do pierwszego uruchomienia proponujemy użycie danych dostępnych publicznie, np. zbioru Retail.xlsx z repozytorium danych Machine Learning MCI:
https://archive-beta.ics.uci.edu/ml/datasets#retail
Zbiór zawiera pół miliona transakcji zarejestrowanych pomiędzy 01/12/2010 a 09/12/2011 w brytyjskim sklepie internetowym.
Pierwszym krokiem jest wczytanie pliku, który zawiera dane o transakcjach (paragonach).
Użyjemy dodatkowo komendy %%time, tzw. magic command, która pozwala ona mierzyć czas wykonywania poszczególnej komórki
%%time
data = pd.read_excel('./data/Online Retail.xlsx')
Wall time: 56.7 s
Wybieramy tylko kolumny z numerami paragonów oraz kodami produktów
data = data[['InvoiceNo', 'StockCode']]
Następnie zmieniamy nazwy kolumn na order_id i product_id ze względu na to że w poniższym kodzie będziemy się właśnie takimi posługiwać
data.columns = ['order_id', 'product_id']
Za pomocą funkcji head() wyświetlamy 5 pierwszych wierszy żeby podejrzeć dane. Będziemy tą operację wykonywali wielokrotnie, dla sprawdzenia poprawności wykonanej operacji.
data.head()
|
order_id |
product_id |
| 0 |
536365 |
85123A |
| 1 |
536365 |
71053 |
| 2 |
536365 |
84406B |
| 3 |
536365 |
84029G |
| 4 |
536365 |
84029E |
Sprawdźmy statystykę danych załadowanych do tzw. DataFrame czyli ramki danych. Dane przechowywane w DataFrame, są traktowane jak tabela danych.
Używamy do tego funkcji info(). Jak widać mamy około 0.5 mln linii paragonowych.
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 541909 entries, 0 to 541908
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 order_id 541909 non-null object
1 product_id 541909 non-null object
dtypes: object(2)
memory usage: 8.3+ MB
3. Przygotowanie danych
Przygotowanie danych ma na celu przekształcenie ich do postaci wymaganej przez funkcję wykonującą analizę, oraz ograniczenie do zbioru danych istotnych, tak aby analizę udało się wykonać w dostępnym środowisku.
W kolejnych etapach, operacje przygotowania danych będziemy wykonywali w skrypcie Qlik Sense.
Poniżej kilka funkcji pomocniczych, które będą przydatne przy przygotowaniu danych.
def encode(x):
if x <= 0:
return 0
if x >= 1:
return 1
def set_to_str(myset):
return ','.join(list(myset))
def str_concat(str1,str2):
return str1 + ' -> ' + str2
Do zliczania transakcji i liczenia częstotliwości występowania produktów, potrzebna nam będzie dodatkowa kolumna ze stałą wartością 1.
data['Qty']=1
Utworzymy teraz DataFrame o nazwie products z listą unikalnych produktów i liczbą wystąpień każdego z nich a następnie posortujemy je od najczęściej występujących.
products może być przydatny przy kolejnych krokach, kiedy okaże się że rozmiar zbioru do analizy jest zbyt duży.
%%time
products = pd.DataFrame(data.groupby(['product_id'])['Qty'].sum().sort_values(ascending=False))
Wall time: 43.8 ms
products.info()
<class 'pandas.core.frame.DataFrame'>
Index: 4070 entries, 85123A to m
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Qty 4070 non-null int64
dtypes: int64(1)
memory usage: 63.6+ KB
products.head()
|
Qty |
| product_id |
|
| 85123A |
2313 |
| 22423 |
2203 |
| 85099B |
2159 |
| 47566 |
1727 |
| 20725 |
1639 |
Liczba wystąpień produktów ma znaczenie w kontekście ilości wszystkich transakcji, dlatego utworzymy teraz nową kolumnę ‘freq’ dzieląc ilość wystąpień produktów przez liczbę wszystkich transakcji na produktach.
products['freq'] = products['Qty']/len(data)
Ustawmy jeszcze format wyświetlania dla kolumn typu float na dziesiętny z 10 miejscami po przecinku zamiast domyślnego naukowego
pd.options.display.float_format = '{:.10f}'.format
products
|
Qty |
freq |
| product_id |
|
|
| 85123A |
2313 |
0.0042682443 |
| 22423 |
2203 |
0.0040652582 |
| 85099B |
2159 |
0.0039840637 |
| 47566 |
1727 |
0.0031868819 |
| 20725 |
1639 |
0.0030244930 |
| … |
… |
… |
| 84031b |
1 |
0.0000018453 |
| 84031a |
1 |
0.0000018453 |
| 82613a |
1 |
0.0000018453 |
| 20950 |
1 |
0.0000018453 |
| m |
1 |
0.0000018453 |
4070 rows × 2 columns
Istnieje 4070 produktów i tak duży zbiór może być problemem dla funkcji wykonującej analizę apriori.
Aby ograniczyć liczbę wierszy tylko do produktów istotnych, czyli występujących w zbiorze danych z zakładaną minimalną częstotliwością tworzymy nowy DataFrame, ustalając minimalną wartość częstotliwości na poziomie 0.0001. W ten sposób ograniczamy zbiór do 2133 najczęściej kupowanych produktów.
W praktyce analizę koszykową wykonuje się często na zdecydowanie większych zbiorach danych, ale też za produkty nieistotne uznaje się często występujące w transakcjach znacznie częściej niż użyta tu wartość progowa 0.0001.
products_top = products[products['freq']>0.0001]
products_top.info()
<class 'pandas.core.frame.DataFrame'>
Index: 2133 entries, 85123A to 84086C
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Qty 2133 non-null int64
1 freq 2133 non-null float64
dtypes: float64(1), int64(1)
memory usage: 50.0+ KB
Tak przygotowane dane mogą być już użyte do wykonania analizy koszykowej.
Analiza koszykowa algorytmem Apriori
Dalsza analizę koszykową można wykonać za pomocą metody Apriori. Wymaga ona aby w wierszach danych wejściowych w kolejnych wierszach znajdowały się paragony (w tym przypadku kolumna order_id), natomiast każdy produkt musi mieć oddzielną kolumnę, co wymaga przekształcenia tabeli. W komórkach tabeli muszą się znajdować wartości:
- 1 – jeśli produkt wystąpił na tym paragonie
- 0 – w przeciwnym wypadku
Rozmiar macierzy, która musiałaby powstać po przekształceniu może być za duży i operacja może się nie powieść z powodu braku zasobów. Dlatego należy ograniczyć ilość kolumn (produktów) lub wierszy (transakcji). W wyniku operacji będącej odpowiednikiem join po product_id między najczęściej występującymi produktami products_top oraz całym zbiorem transakcji data otrzymujemy ograniczony zbiór o nazwie data_reduced
%%time
data_reduced = pd.merge(data, products_top, how='inner', on=['product_id'])
Wall time: 105 ms
data_reduced.head()
|
order_id |
product_id |
Qty_x |
Qty_y |
freq |
| 0 |
536365 |
85123A |
1 |
2313 |
0.0042682443 |
| 1 |
536373 |
85123A |
1 |
2313 |
0.0042682443 |
| 2 |
536375 |
85123A |
1 |
2313 |
0.0042682443 |
| 3 |
536390 |
85123A |
1 |
2313 |
0.0042682443 |
| 4 |
536394 |
85123A |
1 |
2313 |
0.0042682443 |
Kilka przekształceń żeby doprowadzić do formatu kolumn jak w oryginalnym data.
data_reduced = data_reduced[['order_id', 'product_id', 'Qty_x']]
data_reduced.columns = ['order_id', 'product_id', 'Qty']
data_reduced.head()
|
order_id |
product_id |
Qty |
| 0 |
536365 |
85123A |
1 |
| 1 |
536373 |
85123A |
1 |
| 2 |
536375 |
85123A |
1 |
| 3 |
536390 |
85123A |
1 |
| 4 |
536394 |
85123A |
1 |
DataFrame data_reduce ma teraz mniej wierszy, ale co ważniejsze, ma też o wiele mniej produktów, co przełoży się na ilość kolumn po pivocie.
%%time
basket = data_reduced.groupby(['order_id', 'product_id'])['Qty'].sum().unstack().reset_index().fillna(0).set_index('order_id')
Wall time: 1.21 s
basket.head()
| product_id |
10002 |
10125 |
10133 |
10135 |
11001 |
15034 |
15036 |
15039 |
16008 |
16016 |
… |
85232D |
90200D |
90209B |
90214A |
C2 |
D |
DOT |
M |
POST |
S |
| order_id |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 536365 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
… |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
| 536366 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
… |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
| 536367 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
… |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
| 536368 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
… |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
| 536369 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
… |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
0.0000000000 |
5 rows × 2133 columns
basket.info()
<class 'pandas.core.frame.DataFrame'>
Index: 24372 entries, 536365 to C581569
Columns: 2133 entries, 10002 to S
dtypes: float64(2133)
memory usage: 396.8+ MB
Powstały DataFrame zajmuje 396MB posiadając 24372 wierszy i 2133 kolumn.
W tablicy wynikowej wszystkie wartości większe niż 1, muszą być zmienione w 1.
Można do tego użyć funkcji zdefiniowanej poniżej:
def encode(x): if x <= 0: return 0 if x >= 1: return 1
i wywoływanej
basket = basket.applymap(encode)
Jednak jest to metoda bardzo powolna i zdarza się, że nie zostaje ukończona ze względu na ograniczenia pamięci. Jak łatwo wyliczyć 3 mln wierszy razy 500 kolumn daje 1,5 mld komórek dla każdej z nich jest wołana funkcja. Ponadto funkcja applymap musi utworzyć kopie data frame a dopiero ja przypisać co wymaga dużych zasobów pamięci.
Dlatego lepiej zastosować metodę wywołującą funkcję dla każdej kolumny indywidualnie, według zadanych warunków.
%%time
for col in basket.columns:
basket.loc[basket[col] >= 1, col] = 1
basket.loc[basket[col] <= 0, col] = 0
Wall time: 1.47 s
basket.info()
<class 'pandas.core.frame.DataFrame'>
Index: 24372 entries, 536365 to C581569
Columns: 2133 entries, 10002 to S
dtypes: float64(2133)
memory usage: 396.8+ MB
Właściwe wykonanie analizy koszykowej wymaga podania przygotowanego zestawu danych oraz wskazania kolejno minimalnych wartości parametrów support i lift, powyżej których wyniki uznawane będą za istotne. Wartości tą trzeba ustalić metodą kolejnych prób, oceniając ilość i parametry zidentyfikowanych reguł.
Pierwszym krokiem jest wygenerowanie listy kombinacji najczęściej występujących produktów pojedynczo lub w parach lub trójkach itd.
%%time
frequent_itemsets = apriori(basket, min_support=0.02, use_colnames=True)
Wall time: 5.57 s
frequent_itemsets
|
support |
itemsets |
| 0 |
0.0201930502 |
(15036) |
| 1 |
0.0271814672 |
(20685) |
| 2 |
0.0205405405 |
(20711) |
| 3 |
0.0336679537 |
(20712) |
| 4 |
0.0260231660 |
(20713) |
| … |
… |
… |
| 215 |
0.0224710425 |
(23203, 85099B) |
| 216 |
0.0211969112 |
(23300, 23301) |
| 217 |
0.0228957529 |
(85099C, 85099B) |
| 218 |
0.0210424710 |
(85099F, 85099B) |
| 219 |
0.0211969112 |
(22697, 22698, 22699) |
220 rows × 2 columns
frequent_itemsets = frequent_itemsets.sort_values("support",ascending=False)
frequent_itemsets.reset_index(drop=True, inplace=True)
Drugim krokiem jest wygenerowanie reguł asocjacyjnych. Przyjmuje się, że produkty mogą być łączone w zestawy, jeśli dla łączącej je reguły parametr lift jest co najmniej równy 1.
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
rules
|
antecedents |
consequents |
antecedent support |
consequent support |
support |
confidence |
lift |
leverage |
conviction |
| 0 |
(22386) |
(85099B) |
0.0505087806 |
0.0876005252 |
0.0341785656 |
0.6766856214 |
7.7246753939 |
0.0297539699 |
2.8220194811 |
| 1 |
(85099B) |
(22386) |
0.0876005252 |
0.0505087806 |
0.0341785656 |
0.3901639344 |
7.7246753939 |
0.0297539699 |
1.5569614082 |
| 2 |
(22697) |
(22699) |
0.0433694403 |
0.0459543739 |
0.0321680617 |
0.7417218543 |
16.1403973510 |
0.0301750462 |
3.6938689627 |
| 3 |
(22699) |
(22697) |
0.0459543739 |
0.0433694403 |
0.0321680617 |
0.7000000000 |
16.1403973510 |
0.0301750462 |
3.1887685322 |
| 4 |
(21931) |
(85099B) |
0.0492778598 |
0.0876005252 |
0.0300754965 |
0.6103247294 |
6.9671355057 |
0.0257587301 |
2.3414354044 |
| … |
… |
… |
… |
… |
… |
… |
… |
… |
… |
| 91 |
(85123A) |
(21733) |
0.0921549319 |
0.0309371410 |
0.0202691613 |
0.2199465717 |
7.1094666380 |
0.0174181512 |
1.2423031857 |
| 92 |
(20725) |
(23206) |
0.0659773511 |
0.0430411948 |
0.0201050386 |
0.3047263682 |
7.0798770684 |
0.0172652945 |
1.3763772440 |
| 93 |
(23206) |
(20725) |
0.0430411948 |
0.0659773511 |
0.0201050386 |
0.4671115348 |
7.0798770684 |
0.0172652945 |
1.7527544879 |
| 94 |
(20723) |
(20724) |
0.0301165272 |
0.0430822255 |
0.0201050386 |
0.6675749319 |
15.4953678474 |
0.0188075516 |
2.8785969118 |
| 95 |
(20724) |
(20723) |
0.0430822255 |
0.0301165272 |
0.0201050386 |
0.4666666667 |
15.4953678474 |
0.0188075516 |
1.8185315116 |
96 rows × 9 columns
W powyższym przykładzie uzyskaliśmy zbiór 96 reguł asocjacyjnych, łączących dwa produkty. i opisanych siedmioma parametrami.
Dodatkowo, dla wygody przy interpretacji wyników, tabelę warto uzupełnić o kolumnę z nazwą reguły np. będącą zlepkiem kodów występujących w regule produktów.
rules['association_rule'] = rules.apply(
lambda row: str_concat(row['antecedents'], row['consequents']),
axis=1
)
Utworzenie pomocniczej tabeli pozwalającej na podstawie
product_rule_L = rules[['association_rule','antecedents']]
product_rule_L['Role'] = 'Antecedent'
product_rule_L.columns = ['association_rule', 'ArticleName','Role']
product_rule_R = rules[['association_rule','consequents']]
product_rule_R['Role'] = 'Consequent'
product_rule_R.columns = ['association_rule', 'ArticleName','Role']
product_rule = pd.concat([product_rule_L,product_rule_R])
Zapisanie reguł do plików tekstowych, skąd mogą być załadowane do Qlik Sense.
rules.to_csv(‘rules.csv’, index=False) product_rule.to_csv(‘rule_items.csv’, index=False)
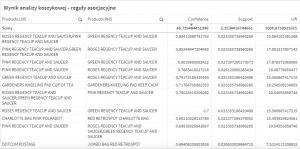
Reguły asocjacyjne wygenerowane dla danych użytych w tym przykładzie, bezpośrednio po załadowaniu do Qlik Sense.
Podsumowanie
Przedstawiliśmy wykonanie analizy koszykowej algorytmem apriori wyłącznie przy użyciu Pythona.
Analiza wykonana na zbiorze danych testowych, liczącym pół miliona rekordów, ograniczonym do produktów występujących częściej niż w promilu transakcji, zidentyfikowała 96 istotnych reguł asocjacyjnych, czyli powiązań pomiędzy produktami.
Poziom istotności ustalony został empirycznie na:
- istotne produkty, biorące udział w analizie – o częstotliwości występowania w paragonach powyżej 0,0001
- istotne asocjacje, brane pod uwagę a tworzeniu reguł – o parametrze support wyższym niż 0,02
- istotne reguły, wchodzące do wyniku analizy – o parametrze lift wyższym niż 1.
W kolejnej części przedstawimy jak wykorzystać Qlik Sense do przygotowania danych, analizy wyników, oraz jak połączyć te dwa narzędzia przy pomocy konektora SSE, aby wymiana danych mogła się odbywać na bieżąco, w trakcie pracy użytkowników Qlika.
Czytaj także: Analiza koszykowa



