W poprzednich wpisach pokazywałem niepoprawne wizualizacje danych wynikające nie tyle ze złych intencji, co z braku profesjonalizmu. Zgodnie z obietnicą dzisiaj chciałbym przedstawić kilka wykresów i infografik, które spokojnie mogłyby zostać umieszczone w opublikowanej 69 lat temu książce Darrela Huffa „How to lie with statistics?”. Nie zawsze jest oczywiste czy za błędami w wizualizacji danych statystycznych stoi niekompetencja, czy intencja. Dlatego wybrałem takie, w których intencja manipulacji nie budzi wątpliwości.
Nietrudno się zorientować, że w takich praktykach przodują politycy, ale znajdziemy też innych twórców wykresów statystycznych świadomie wprowadzających odbiorców w błąd. Ich wspólną cechą jest to, że autorzy chcą uzasadnić z góry przyjętą tezę za pomocą wizualizacji danych. Przyjrzyjmy się zatem kilku przykładom
Korelacja oznacza jedynie, że istnieje korelacja
Częste jest wnioskowanie na podstawie fałszywej korelacji – istniejącej między zmiennymi, które nie są od siebie zależne. Wiele z nich jest dość zabawnych (niektóre można obejrzeć w tym miejscu: https://www.tylervigen.com/spurious-correlations). Moją ulubioną jest korelacja pomiędzy liczbą filmów z Nicolasem Cage’m, a liczbą utonięć w USA na skutek wpadnięcia do basenu.
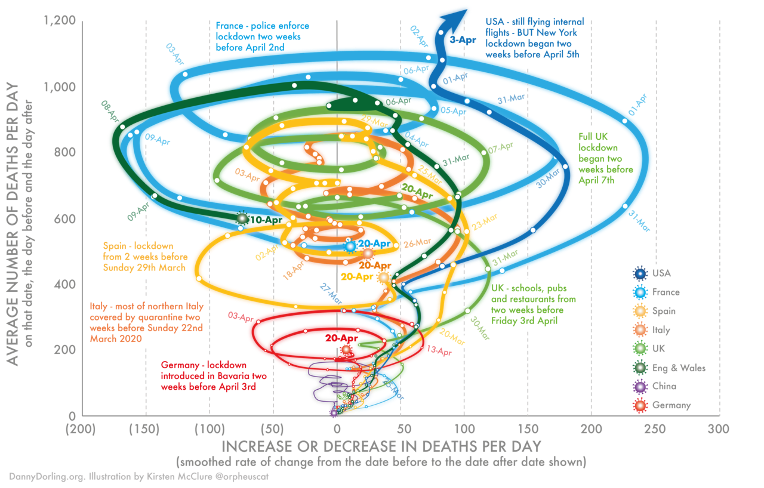
Poniżej jeden z bardzo wielu przykładów sytuacji, gdy autor na wykresie korelacje pokazuje, chociaż de facto ona nie istnieje. Problem polega jednak na tym, że autorem tej wizualizacji danych jest Apple, którego trudno podejrzewać o brak kompetencji dotyczących analizy danych.
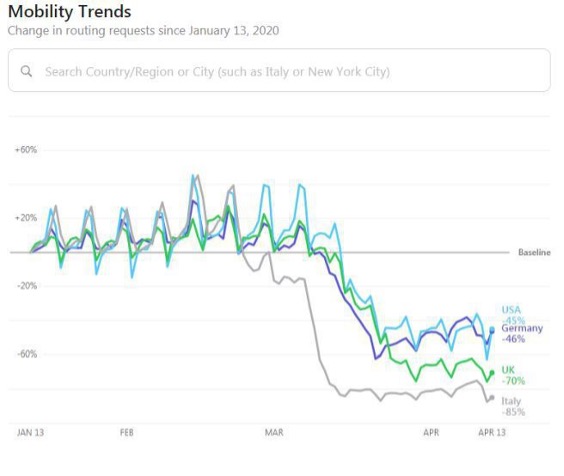
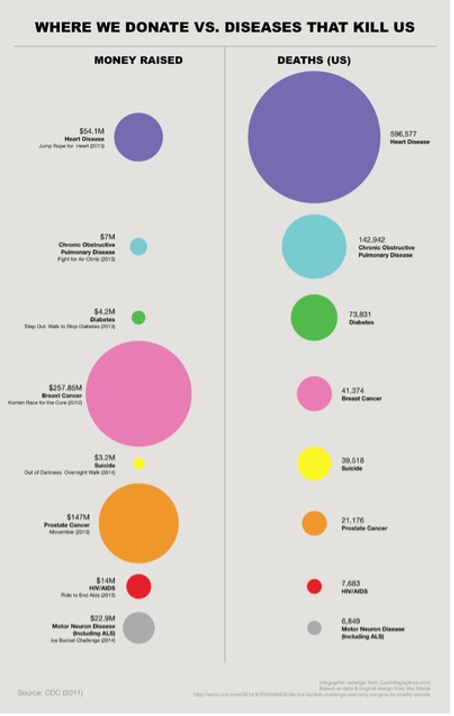
Apple za pomocą tego wykresu pokazywał, że dane zbierane przez firmę w aplikacjach (w tym wypadku Apple Maps) mają znaczenie w monitorowaniu skutków pandemii. Wykres pokazuje korelację wyszukiwania destynacji wyjazdowych z okresem lockdownu, z czego ma wynikać, że w jego trakcie mniej wychodziliśmy z domu. Być może tak było, jednak zakładanie, że mapy używamy za każdym razem, gdy wychodzimy z domu prowadzi do fałszywej korelacji. Map używamy raczej wtedy, gdy udajemy się w miejsce, do którego nie wiemy, jak dotrzeć. Z takich danych możemy zatem wnioskować, że podróżowaliśmy mniej (nic dziwnego, skoro lockdown objął także komunikację), ale na pewno nie to, że wychodziliśmy rzadziej z domu (idąc do pobliskiego parku mało kto używa mapy).
W tym wypadku „kłamstwo” miało najprawdopodobniej przyczynę marketingową. Wszystko, co dotyczyło pandemii było w 2020 roku czytane bardzo uważnie, zatem każda marka pokazująca dane dotyczące tego tematu miała gwarantowaną bezpłatną promocję. Tym bardziej, gdy firma sugeruje, że dane przez nią zbierane mają znaczenie w walce z pandemią.
Skala wszystko wytrzyma?
Kolejny przykład jest wart uwagi nie tylko z tego powodu, że pochodzi z podręcznika szkolnego, ale również, dlatego że Darrell Huffa takiego sposobu kłamstwa nie opisał. Co więcej, autorzy wizualizacji danych statystycznych podpierają się autorytetem wybitnego naukowca.
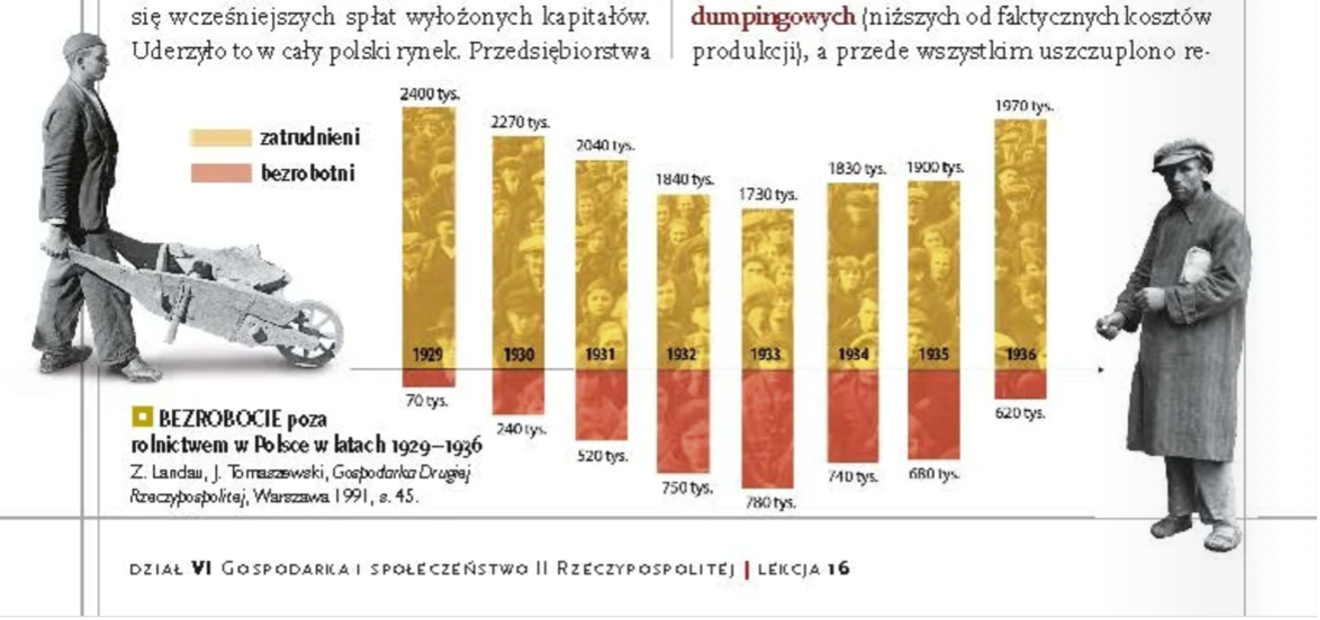
Wykres pochodzi z podręcznika szkolnego i miał być ilustracją efektów polityki gospodarczej w przedwojennej Polsce. Nie ma wątpliwości, że światowy kryzys gospodarczy w 1929 roku spowodował gwałtowny wzrost bezrobocia także w Polsce. Jednak wykres pokazuje równie szybką poprawę sytuacji w latach 30-tych, czego dane akurat nie potwierdzają.
Jak robią to autorzy? Bezrobocie pokazują w liczbach bezwzględnych, a nie jako stopę (odsetek aktywnych zawodowo). Rynek pracy, z powodu procesów demograficznych, zmienia się pod względem liczby osób aktywnych zawodowo, zatem dane przedstawiane w liczbach bezwzględnych w kolejnych latach są nieporównywalne. Co więcej, wartości dodatnie (liczbę bezrobotnych) autorzy na wykresie pokazali jako wartości poniżej zera.
I wreszcie nie trzeba sokolego wzroku, aby zorientować się, że coś jest nie tak ze skalą. Proponuję porównać słupek reprezentujący 70 tys. bezrobotnych w 1929 roku i 620 tys. w roku 1936.
W konsekwencji spadek bezrobocia wydaje się znacznie większy niż był w rzeczywistości. A pamiętajmy, że czytelnikiem tego podręcznika są 15-latki.
Trend, którego nie ma?
Statystyki chorób budzą lęk i dlatego dobrze „sprzedają” treści publikowane w mediach. Poniżej kolejna wizualizacja danych statycznych na temat wzrostu liczby chorych na odrę. Jest to świetna ilustracja drugiego, najczęstszego po manipulacji skalą, sposobu kłamania za pomocą statystyk, czyli wybieranie jedynie tych danych, które potwierdzają naszą tezę („cherry picking”).
Telewizja TVN w alarmistycznym materiale dotyczącym wzrostu liczby chorych pokazała wykres, który ma tą tezę uzasadniać. W tym celu z trzynastoletniego szeregu czasowego wybrała jedyne cztery lata, które „potwierdzają” trend wzrostowy.
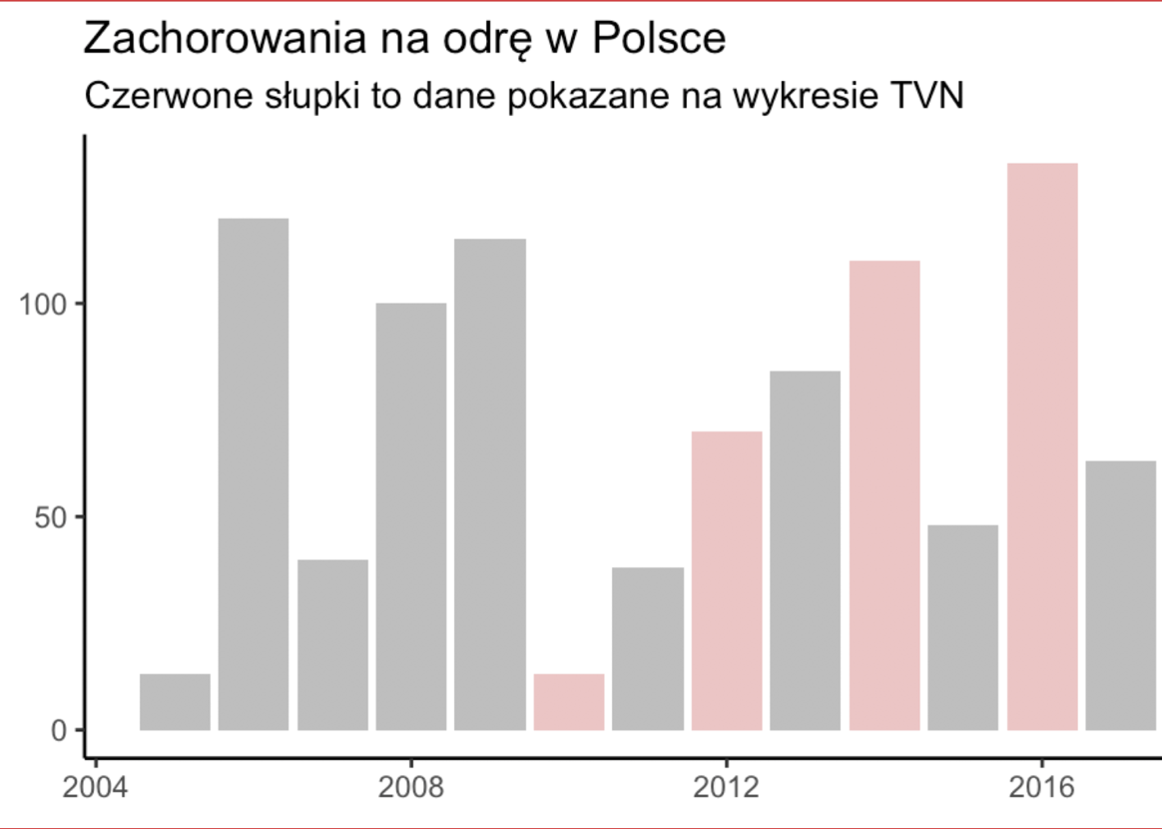
Problem z wyłapywaniem takich manipulacji na ekranie telewizora polega na tym, że wykres pojawia się najwyżej na kilkanaście sekund i jego dokładniejsza analiza jest trudna.
Znowu – nie chcę pisać, że nie mamy problemu z liczbą zachorowań na odrę. Mamy i to duży. Wynika on z coraz większego odsetka osób nieszczepiących dzieci. Zjawisko to na infografice fantastycznie pokazał The Guardian (https://www.theguardian.com/society/ng-interactive/2015/feb/05/-sp-watch-how-measles-outbreak-spreads-when-kids-get-vaccinated).
Dane pokazujące skalę zagrożenia dużo lepiej niż zrobił TVN są łatwo dostępne. Wystarczy pokazać liczbę zakażeń i śmiertelność w długim szeregu czasowym, obejmującym także okres przed wprowadzeniem obowiązkowych szczepień. W dobrej sprawie nie trzeba kłamać. Wystarczy sięgnąć po rzetelne dane.
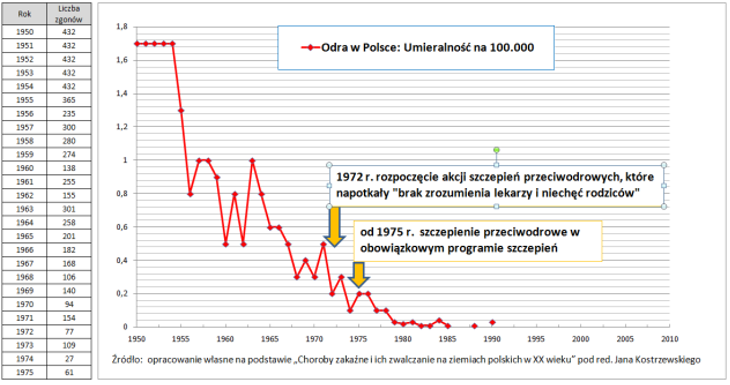
Bardzo dynamiczny wzrost
Poza manipulacją skalą możemy też spotkać manipulacje dynamiką wzrostu. Autorom infografiki poniżej nie wystarcza już pokazanie słupków odciętych na poziomie około 1000 zł. Nie wystarcza wzmocnienie tego zabiegu poprzez prezentowanie wzrostu składki przy pomocy pola i koloru słupka. Zasugerowali też, korzystając ze środków graficznych, geometryczny wzrost składki. Strzałka ponad wykresem pokazuje, że rośnie ona coraz szybciej. Naprawdę wygląda groźnie.
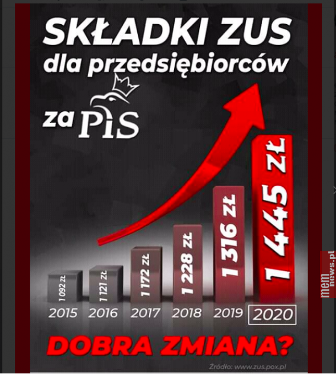
Nie chcę powiedzieć, że składki na ZUS nie rosną i nie są bardzo dużym obciążeniem dla przedsiębiorców. Jesteśmy przyzwyczajeni do tego, że politycy manipulują faktami. Jednak w tym przypadku weszli na wyżyny i zdecydowanie zasłużyli na umieszczenie tej twórczości w kolejnym wydaniu książki Huffa.
Temat rzeka: Statystyki i koronawirus. Oto kolejny przykład nierzetelnej wizualizacji wykorzystanej w telewizji (tym razem w TVP), chociaż jej autorem jest Kancelaria Premiera. Poniższy wykres ma uzasadnić decyzje rządu o zakresie ograniczeń w czasie pandemii. Po obejrzeniu wizualizacji danych pokazanej poniżej możemy nabrać przekonania, że „Polski rząd oparł swoje decyzje na badaniach amerykańskich naukowców”.

Znowu, ta manipulacja jest wielopoziomowa. Po pierwsze mamy tu skalę, która wprawdzie merytorycznie została użyta poprawnie, jednak zaryzykuję tezę, że 99,99% widzów Wiadomości TVP nie tylko nie rozumie skali logarytmicznej, ale nawet nie zauważy, że zastosowano skalę inną niż liniowa.
Najważniejsze jest jednak to, że wykres pokazuje coś zupełnie innego, niż obiecuje jego tytuł.
Wizualizacja nie dotyczy tego, że ryzyko zakażenia w hotelu jest większe niż np. w kościele, co sugeruje rządowa grafika. Wykres natomiast przedstawia liczbę dodatkowych zakażeń w przypadku zniesienia ograniczeń (na podstawie danych z USA). Oczywiście liczba bezwzględna zakażeń jest ważna, jednak nazywanie jej „ryzykiem” nie ma nic wspólnego z rzeczywistością. Ryzyko, a właściwie prawdopodobieństwo, pokazujemy za pomocą wartości z przedziału 0-1 (wyrażanej też w procentach) lub wskaźnikach liczby zdarzeń przypadającą na liczbę osób. Jeżeli w przypadku pokazania prawdopodobieństwa w USA moglibyśmy nawet próbować wnioskować, na ile konkretnie miejsce ma wpływ na prawdopodobieństwo zakażenia w Polsce, to pokazanie liczb bezwzględnych całkowicie wprowadza w błąd.
Zresztą autorzy raportu, na który powołuje się KPRM prezentują wiele infografik w rzeczywistości pokazujących ryzyko zakażenia. Z ważnych wizualizacji danych statystycznych zawartych w raporcie można dowiedzieć się nie tylko, gdzie ryzyko jest największe, ale także których grup dochodowych problem szczególnie dotyka. Po inne równie ciekawe odsyłam do źródła (https://www.nature.com/articles/s41586-020-2923-3#MOESM1)
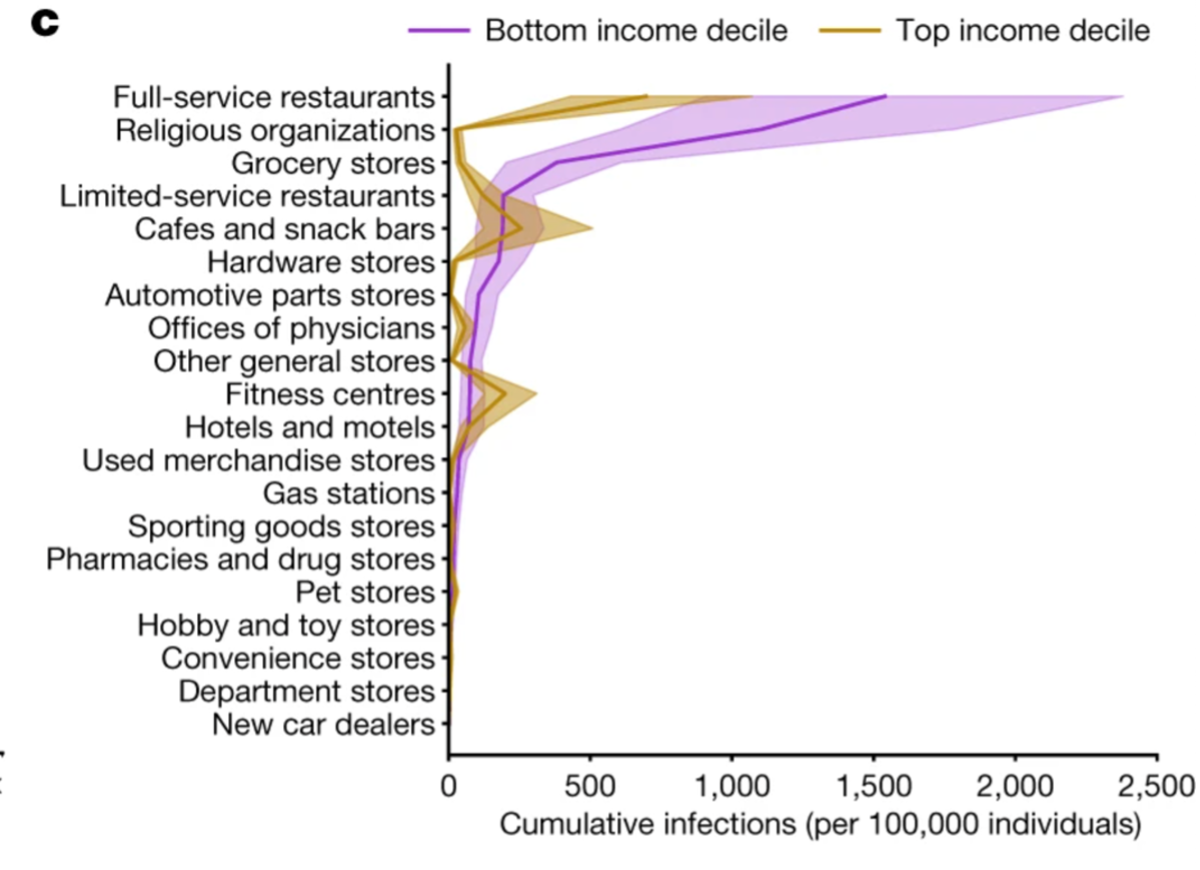
Co jest zaskakujące?
COVID-19 powodował wysyp wizualizacji danych statystycznych, które mniej lub bardziej świadomie wprowadzały w błąd. Zjawisko zrozumiałe, skoro od 100 lat nie mieliśmy do czynienia w pandemią w podobnej skali i nie mamy doświadczeń w mierzeniu takiego zjawiska.
Może stawiam poprzeczkę za wysoko autorom wizualizacji zamieszczonej poniżej, ale Statista to wiodąca firma w obszarze zbierania przetwarzania i udostępniania danych. Niektóre dane udostępniane są bezpłatnie, co służy promocji jej usług.
Tytuł poniższego materiału może wprowadzać nas w błąd, gdyż sugeruje, że nastąpiło jakieś zaskakujące zjawisko…
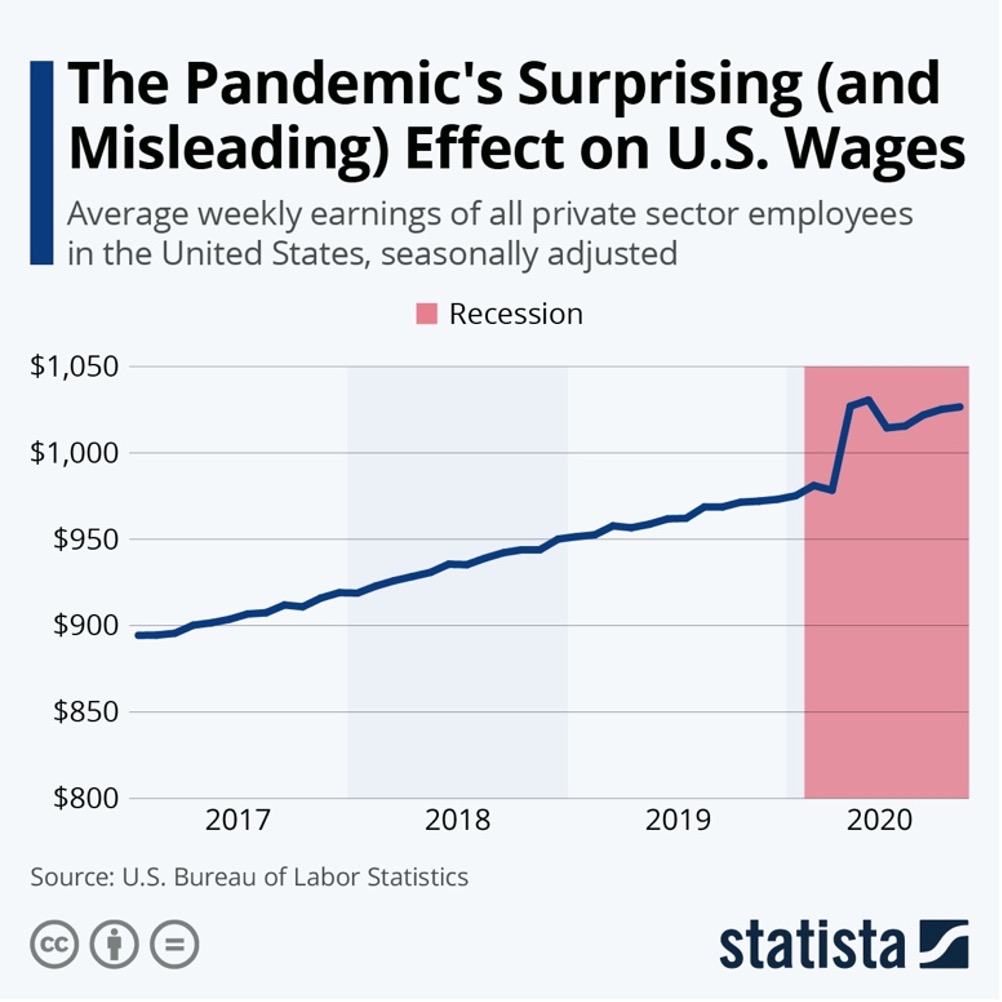
Co jednak widać na wykresie? Zarobki w sektorze prywatnym mają od 2017 roku trend wzrostowy i pandemia tego nie zmienia. Mamy krótkie jego zaburzenie w drugim kwartale 2020, które jednak łatwo wyjaśnić nadzwyczajnym wydarzeniem (zatrzymanie znaczącej części gospodarki).
Jednak, gdy sprawdzimy w danych historycznych, to nie ma żadnej prawidłowości dotyczącej związku recesji z poziomem wynagrodzeń. W pięciu poprzednich amerykańskich recesjach dwukrotnie wynagrodzenia pozostawały na tym samym poziomie, dwukrotnie spadły, a raz wzrosły. Nie ma zatem żadnego powodu, aby dane z 2020 roku uznać za zaskakujące, ponieważ sugerowana zależność nie istnieje.
Co innego z bezrobociem. W zdecydowanej większości przypadków po drugiej wojnie światowej recesja wiązała się z jego wzrostem. To zresztą może nas naprowadzić na trop przyczyny wzrostu przeciętnych wynagrodzeń na początku wywołanej pandemią recesji. Być może przeciętne wynagrodzenia wzrosły, bo pracę straciły głównie osoby gorzej zarabiające? Taką hipotezę mogą potwierdzać dane opublikowane przez The Rand Blog dotyczące Los Angeles.

Niczego istotnego nie dowiadujemy się z wykresu udostępnionego przez Statistę, a sugerowanie na jego podstawie, że firma ma jakieś szczególne kompetencje analityczne jest nadużyciem. Zaskakujące może być jedynie to, że Statista coś takiego robi.
Fake newsy i sposoby na ich obnażenie
Wiele z przykładów, które pokazałem powyżej mogłyby być określone jako fake newsy. Stanowią one ogromny problem dla jakości debaty publicznej, wprowadzają w błąd i wpływają negatywnie na zachowania obywateli. Warto zatem wiedzieć jak zidentyfikować treści, które możemy podejrzewać o to, że są fake newsami.
Jeżeli:
- nie widzimy związku między skorelowanymi zmiennymi,
- na osi czasu są „dziury” dotyczące niektórych okresów,
- widzimy manipulacje skalą,
- całość wygląda zbyt dobrze (pasuje idealnie do tezy),
- obserwacje są prezentowane jako „niezwykłe”
to w takich przypadkach warto sięgnąć do źródła danych, żeby zweryfikować takiego newsa. A jeżeli źródło nie jest podane, to spokojnie możemy założyć, że mamy do czynienia z fake newsem.
W skrócie – możemy przyjąć, że jeżeli coś kwacze jak kaczka, ma dziób jak kaczka i pływa jak kaczka, to najprawdopodobniej jest kaczką.
Zobacz także: Programy do wizualizacji danych